本文最后更新于92 天前,其中的信息可能已经过时,如有错误请发送邮件到939925357@qq.com
GraphSearchNet: Enhancing GNNs via Capturing Global Dependencies for Semantic Code Search(TSE 2023)
论文开源仓库:https://github.com/shangqing-liu/GraphSearchNet
前言:
其实我在粗读的时候发现这篇23年(21年第一版)的论文在codesearchnet数据集的JAVA和python基于MRR指标所达到的水平,其实和21年(20年第一版)的Graphcodebert比较接近,甚至某些方面和泛化性还不如后者,但是作为软件工程的顶会,我认为在benchmark上sota或许不能成为能不能发论文的必要条件,对应技术工程实践可落地性或者其他角度仍然不能忽略。
摘要
本文针对自然语言驱动的语义代码搜索问题,提出了一种新的图神经网络框架 GraphSearchNet。
作者认为现有方法要么将代码与查询视为纯文本序列,忽略结构信息;要么使用 GNN 但难以捕获全局依赖关系。
为此,GraphSearchNet 将源代码和自然语言查询统一建模为图结构,利用 双向 GGNN(BiGGNN)建模局部结构语义,并引入多头注意力机制补充全局语义依赖。
在 CodeSearchNet 的 Java 和 Python 数据集上的实验表明,该方法在多项检索指标上显著优于现有主流方法。
数据集介绍
- 数据集来源:CodeSearchNet(公开大规模代码搜索基准)
这里我们已经介绍过来,详见:论文日常阅读笔记——CodeSearchNet 2019 – 个人计算机算法学习分享
- 编程语言:Java、Python
- 数据规模:
- 超过百万级函数级代码样本
- 每个代码样本配有对应的自然语言函数摘要(summary)
- 训练方式:
- 使用 (代码,函数摘要) 对进行训练
- 使用独立的 99 条真实自然语言查询 进行真实搜索评估
- 任务特点:
- 代码与查询在语法和结构上高度异构
- 查询通常较短但语义抽象
模型构造与训练
模型示意图:
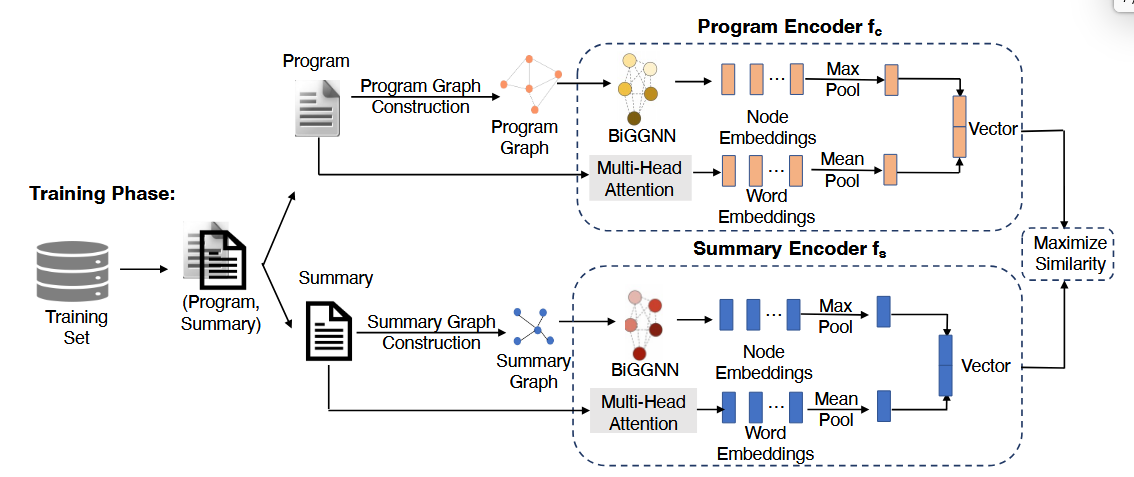
1. 图构造(Graph Construction)
构造图样例:
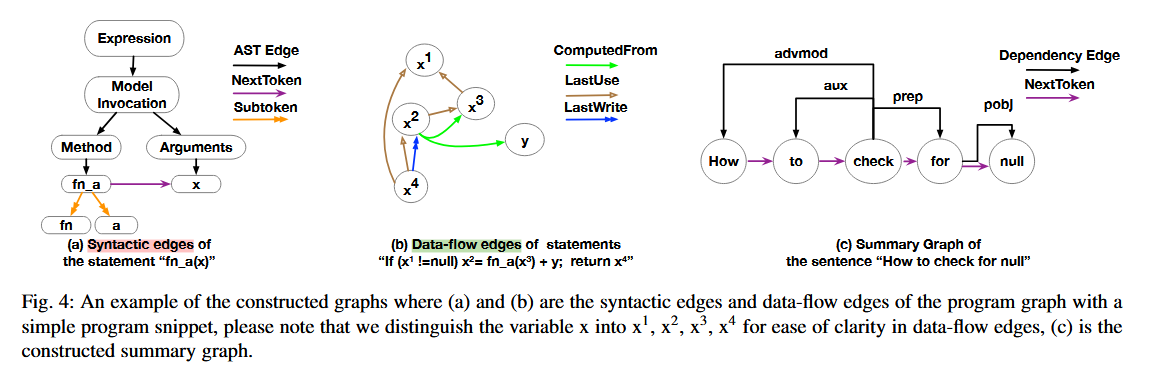
- 代码图(Program Graph)
- 节点:AST 节点 + 子词节点
- 边类型:
- 语法边(AST、NextToken、SubToken)
- 数据流边(LastUse、LastWrite、ComputedFrom)
- 查询图(Summary Graph)
- 基于依存句法分析构建
- 包含依存关系边 + NextToken / SubToken
2. 编码器结构(Encoder)
每个编码器(代码 / 查询)包含两个核心模块:
- BiGGNN(双向门控图神经网络)
- 同时建模入边和出边
- 捕获局部结构与控制/数据依赖信息
- 多头注意力模块
- 直接作用在 token 序列上
- 弥补 GNN 在长程 / 全局依赖建模上的不足
最终将:
- GNN 输出的图级表示
- Attention 输出的全局表示
进行拼接,这里的拼接逻辑核心实现为将二者加入门控机制求和,得到最终向量表示。
3. 训练目标(Training Objective)
- 采用 对比式交叉熵损失
- 目标:
- 拉近正确 (代码,查询) 向量距离
- 拉远无关代码的向量距离
- 相似度度量:余弦相似度
实验结果
1. 整体性能
实验结果:(在整个语料库中检索)
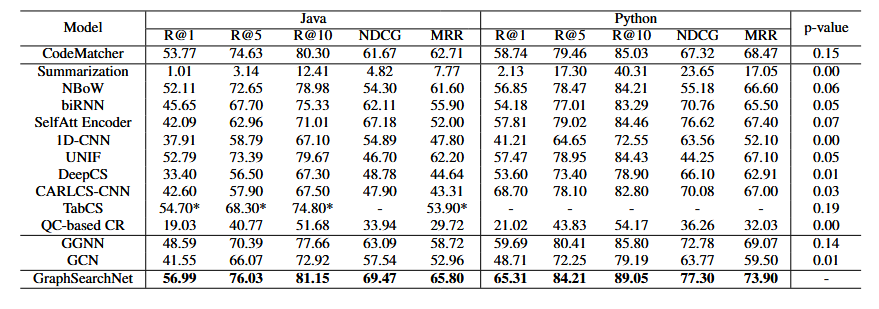
- 在 Java / Python 上:
- R@1、R@5、R@10、MRR、NDCG 均优于所有对比方法
- 明显优于:
- 序列模型(LSTM、CNN、Self-Attention)
- 传统 GNN(GCN、GGNN)
- IR / 混合方法(如 CodeMatcher)
2. 消融实验(Ablation Study)
消融实验结果:
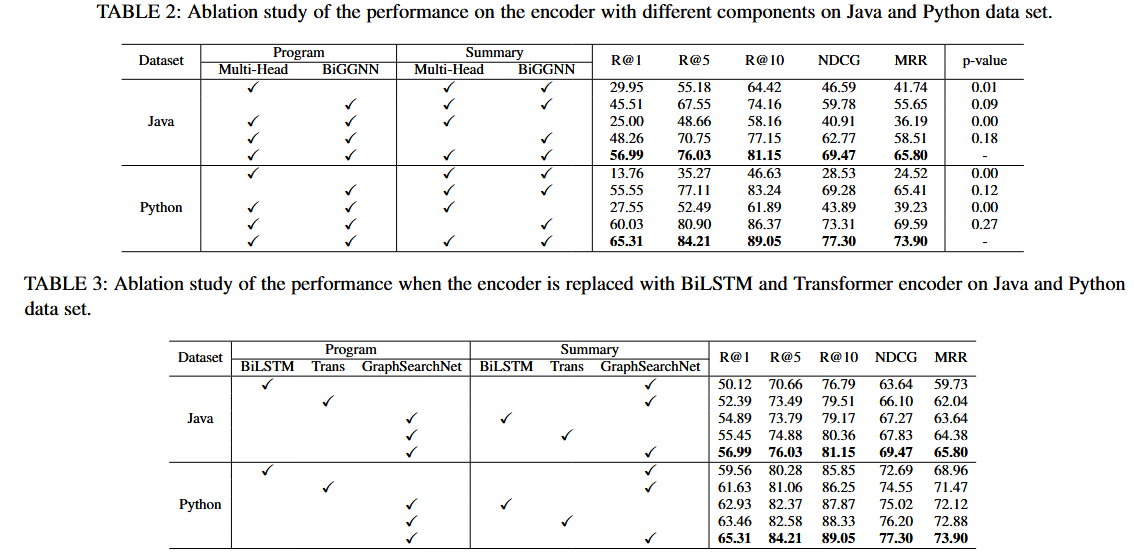
- BiGGNN 是性能提升的核心
- 多头注意力进一步显著增强效果
- 仅用 GNN 或仅用 Attention 都无法达到最佳性能
- 对代码和查询同时进行结构建模优于只结构化代码
3. 真实查询评估
基于codeSearchnet挑战赛结果:
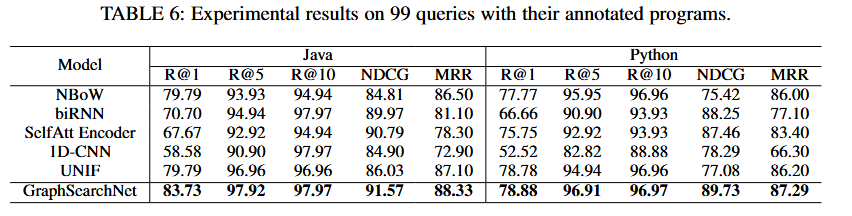
- 在 99 条真实查询上:
- GraphSearchNet 返回的代码语义相关性更高
- 排名质量优于强基线模型
- 同时发现:
- 对极短查询(如只有 1–2 个词)效果下降
论文优点与缺陷
优点(Strengths)
- 问题定位精准
明确指出 GNN 在代码搜索中“局部强、全局弱”的关键缺陷,并提出针对性解决方案。 - 结构对称、设计合理
同时对代码和查询进行图建模,而非只关注代码结构,理论上更严谨。 - 实验充分,结论可信
多语言、多指标、强基线、消融 + 真实查询评测,验证完整。
缺陷与局限(Limitations)
- 对短查询不鲁棒
查询过短时,依存图结构信息不足,图建模优势难以体现。 - 工程复杂度较高
AST + 数据流 + 依存句法 + GNN + Attention,系统实现成本高。 - 与预训练大模型结合不足
未深入探讨与 CodeBERT / LLM 等预训练模型的互补关系。
总结
GraphSearchNet 通过将代码搜索建模为“结构感知的图语义匹配问题”,有效弥补了传统 GNN 的全局依赖缺陷,在语义代码检索任务上取得了稳定且显著的性能提升。


https://shorturl.fm/Q9Gys
https://shorturl.fm/D7GzX
https://shorturl.fm/4o4cz