Beyond Message Passing: Neural Graph Pattern Machine(ICML 2025)
论文链接:[2501.18739] Beyond Message Passing: Neural Graph Pattern Machine
论文开源仓库:GitHub – Zehong-Wang/GPM: Beyond Message Passing: Neural Graph Pattern Machine, ICML 2025
补充知识
1-WL test
1-WL test 指一维WL测试,可以判断两个图是否同构,但是对于强正则图场景下不能正确判断。通常认为传统GNN 的模型图结构判别效果不超过1-WL test,参考资料:Weisfeiler-Lehman图同构测试及其他 – e-yi – 博客园
1-WL test样例:
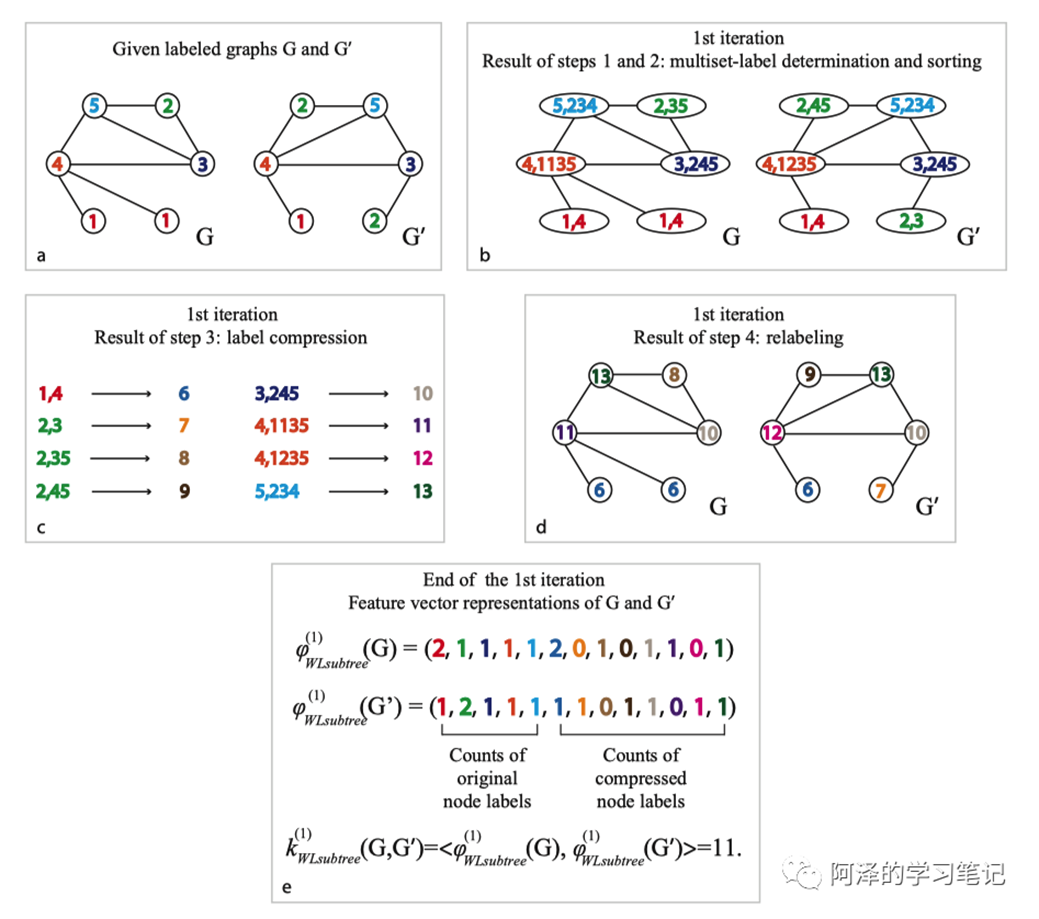
随机游走与匿名游走

一、摘要
本文指出传统基于消息传递(Message Passing)的图神经网络在表达能力、长程依赖建模和可解释性方面存在根本瓶颈,提出了一种不依赖消息传递的图学习新范式——通过直接建模图中的结构模式(graph patterns)来进行表示学习。该方法在多个图学习任务上取得了显著优于现有方法的性能,并展示了更强的表达能力与泛化性。
二、数据集介绍
作者在多种标准图学习任务与数据集上进行了验证,覆盖不同规模与任务类型,包括:
- 节点级任务:节点分类(如 citation / social network 类数据)
这里数据集包括Products、Computer、Arxiv、WikiCS、CoraFull、Deezer、Blog、Flickr和Flickr-S(小型)。我们采用了Chen等人(2023)和Chen等人(2024)的数据集拆分:WikiCS、Flickr、Arxiv和Products的公开分拆;CoraFull和Computer的列车/行李/测试60/20分配;剩余数据集按50/25/25比例分配。
- 边级任务:链接预测
这里的数据集包括:Cora、Pubmed和 ogbl-Collab。遵循 Guo 等人(2023)的做法,我们将边缘分为 80/5/15 的 train/val/test 集,并用 Hits@20 用于 Cora和 Pubmed,Hits@50 用于 ogbl-Collab 进行评估
- 图级任务:图分类与图回归(如分子性质预测)
这里部分的数据集包括:社交网络(IMDB-B、COLLAB、Reddit-M5K、Reddit-M12K)用于分类,分子图(ZINC和 ZINC-Full)用于回归分析。我们用80/10/10的训练/评估/测试分成社交网络,而公开分成则用分子图。
-
特殊评测设置:
- 长程依赖任务(Long-range dependency)
这里的长依赖任务主要是测试GPM是否有传统GNN中的过压缩问题,这里采用的数据集是
TREENEIGHBORSMATCHING benchmark,是一个二叉树结果,根据根节点的度数来分类。- 表达能力/可区分性测试
这里的可区分性测试注意涉及到三个数据集:CSL数据集(Murphy等,2019)包含150个4-正则图,使用1-WL检验时无法区分。EXP数据集(Abboud等,2021)包含600对非同构图,这些图无法通过1-WL或2-WL检验区分。最后,SR25数据集(Balcilar等,2021)包含15个强正则图,每个图有25个节点,即使在3-WL检验下也无法区分。
- OOD(分布外泛化)测试
这里的泛化性测试主要涉及到三个数据集:citation networks——ACM and DBLP(using accuracy as the metric)和social networks——Twitch(using AUC as the metric)
👉 数据集设计的重点在于:直接检验消息传递的局限是否被新方法突破。
三、模型构造与训练
模型工作流:
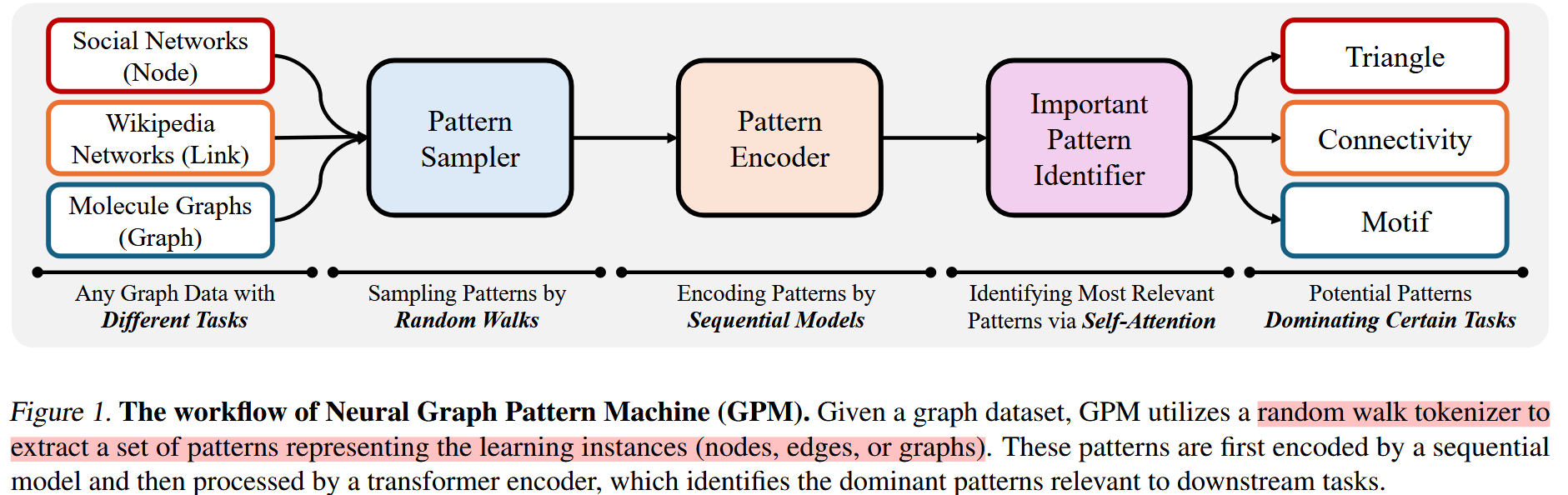
1. 核心思想
跳过节点间逐层消息传递,直接以“图结构模式”为基本建模单元。
2. 模型结构(GPM)
模型核心框架:
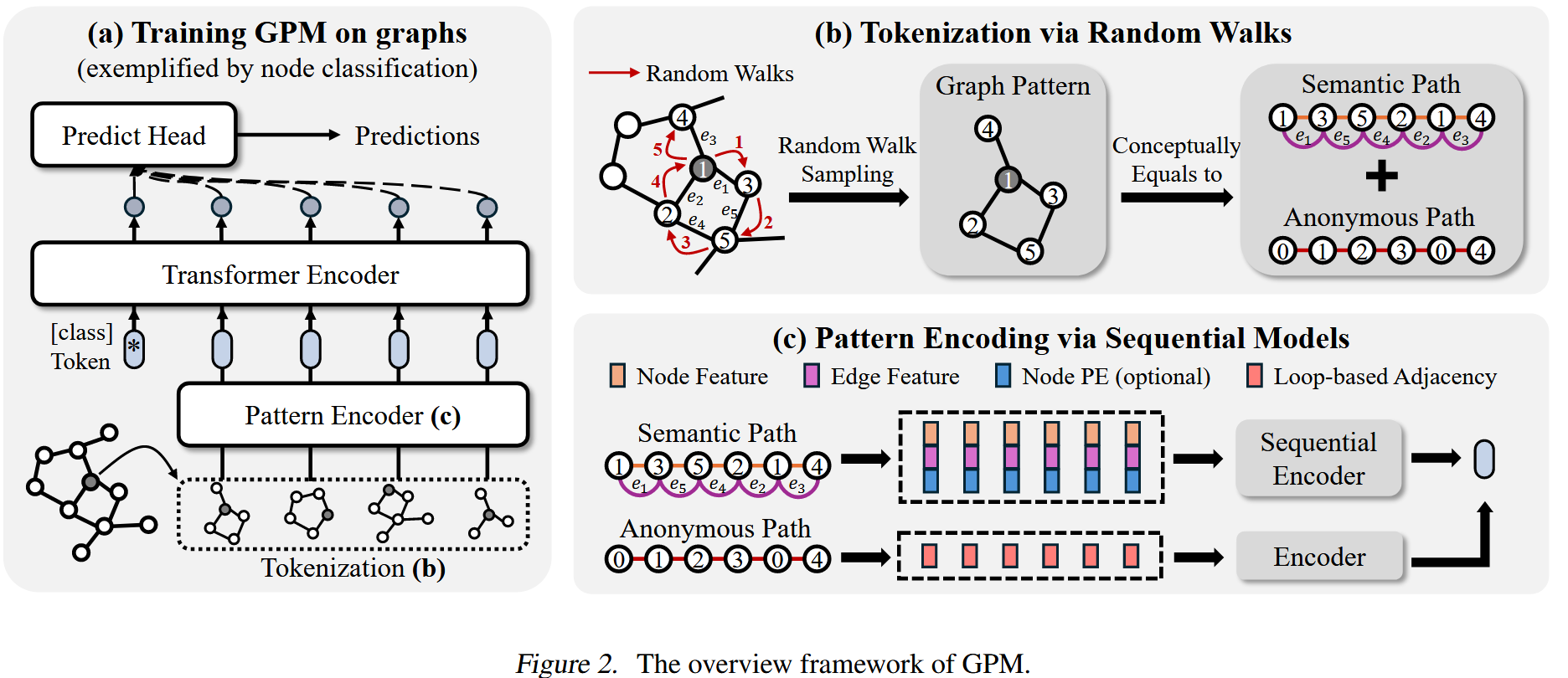
-
模式采样(Pattern Sampling)
- 使用随机游走从图中采样子结构,得到随机游走路径和匿名路径
这里需要注意的是对于不同类型的任务,采样方式也不同:
For node-level tasks, the tokenizer samples k patterns for a node v.
For edge-level tasks, the tokenizer samples k patterns starting from the endpoints u and v of an edge e = (u, v).
For graph-level tasks, the tokenizer samples k patterns for each graph by randomly selecting starting nodes within the graph.
上面的采样是为了同时捕捉:
- 语义路径(semantic path)(节点/边特征)
- 匿名路径(anonymous path)(纯拓扑结构)
-
模式编码(Pattern Encoding)
该部分主要包括两个部分,Semantic path encoding和anonymous path encoding,在正式讲解前,默认对于源图我们已经知道对应节点,边,节点特征矩阵,边特征矩阵的相关信息。

这里特别注意的点有三点,
第一个是最后每个采样得到的图模式生成的embedding结果是语义路径编码和匿名路径编码乘加权系数的和。
第二个是语义路径编码中的节点特征在进入线性单元前先将节点特征向量,边特征向量,位置编码拼接形成了一个综合特征向量矩阵。
第三个是匿名路径编码的时候,每个匿名节点编码向量的我们定义为一个k维的向量,而n个匿名节点对应的特征矩阵Z则为(n*k),而其中对应这个特征矩阵Z中的每一位Zij的定义是判断原匿名路径中的第i个节点和第j个节点是否相同,如果相同则为1,反之为0。所以在输入进GRU编码器前,特征矩阵实际上为一个01矩阵。
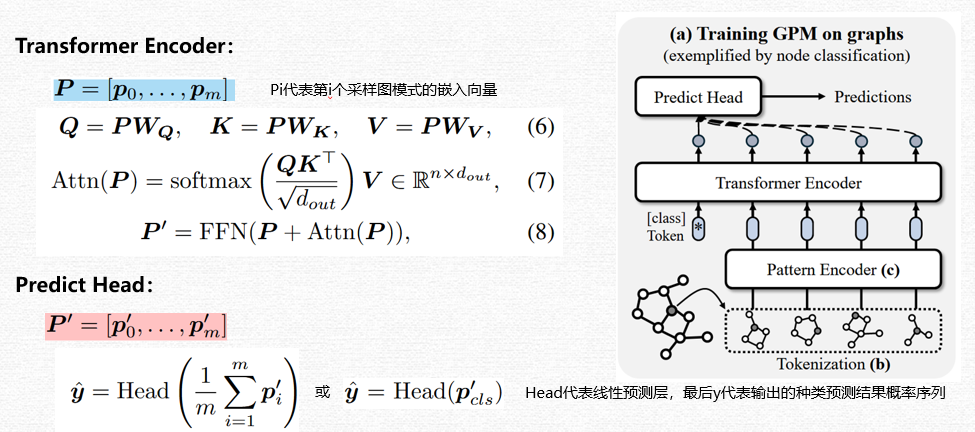
在被模式编码器完成编码之后,我们得到了每个图模式基于随机路径语义和匿名路径语义的综合嵌入向量,接着我们将这个综合语义嵌入向量再输入给一个transformer层,利用其self-attention机制让其识别到真正和下游任务相关的核心图模式。最后再输入给一个预测的线性层,完成最后的下游任务。

3. 训练方式
- 端到端训练
- 使用标准监督学习目标(分类 / 回归损失)
- 可适配节点级、边级和图级任务
四、实验结果
1.整体性能显著优于 SOTA
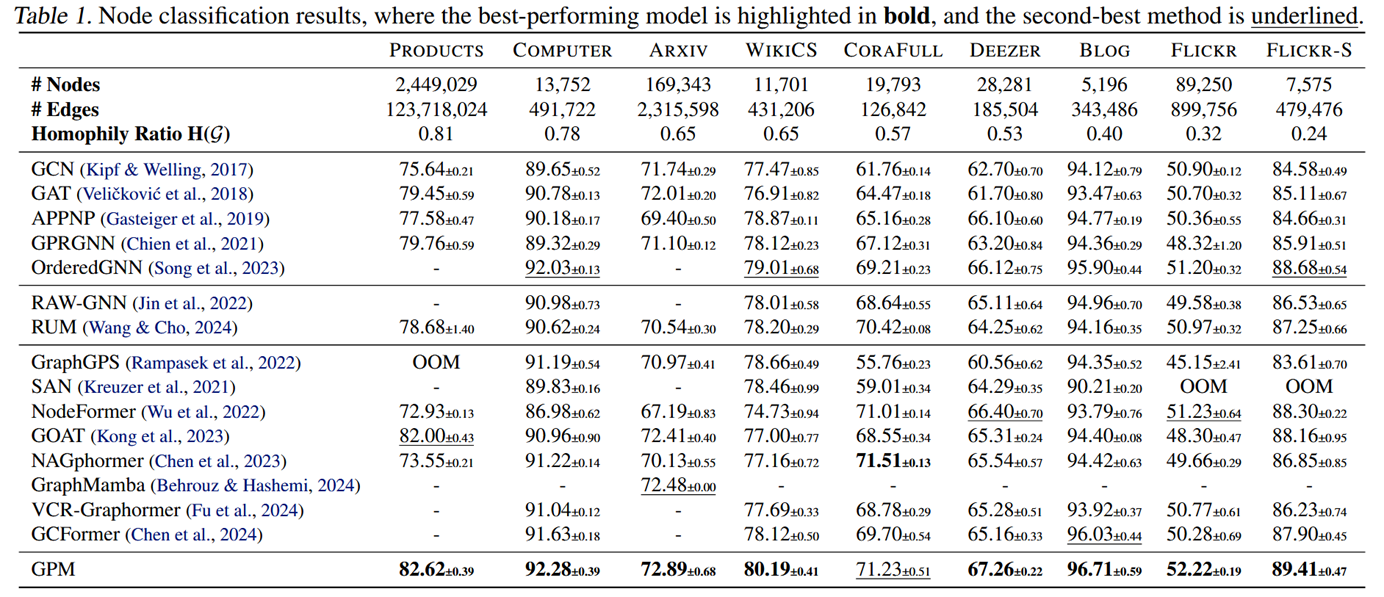
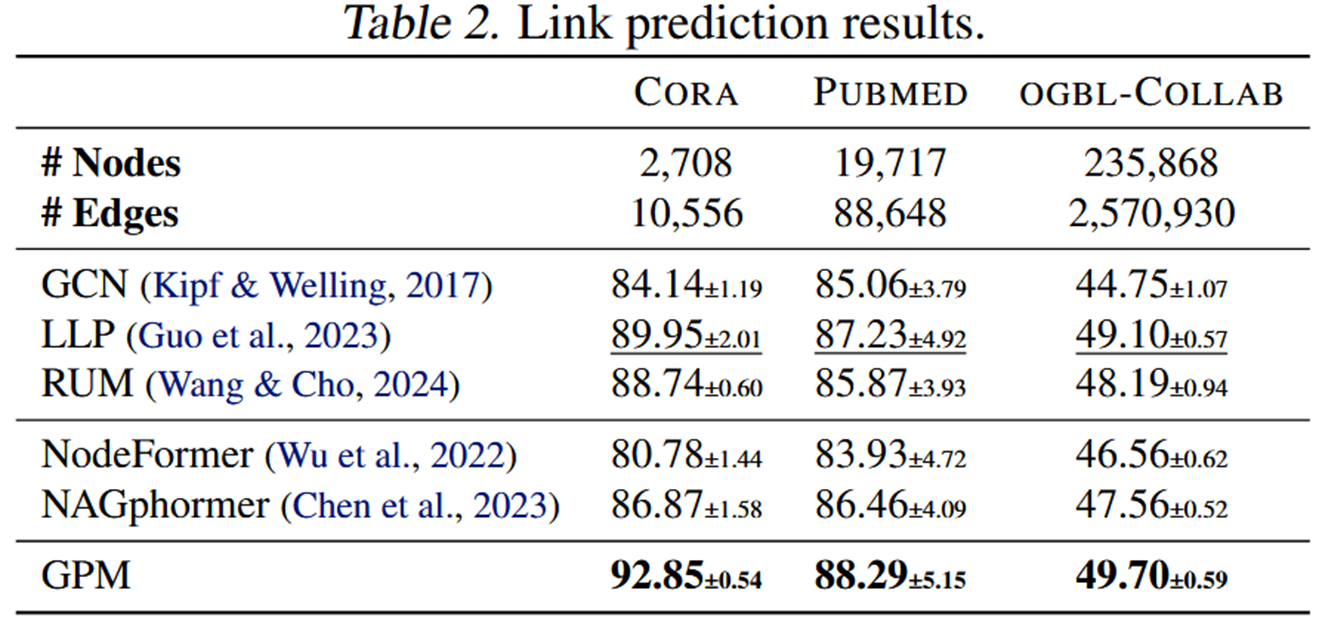
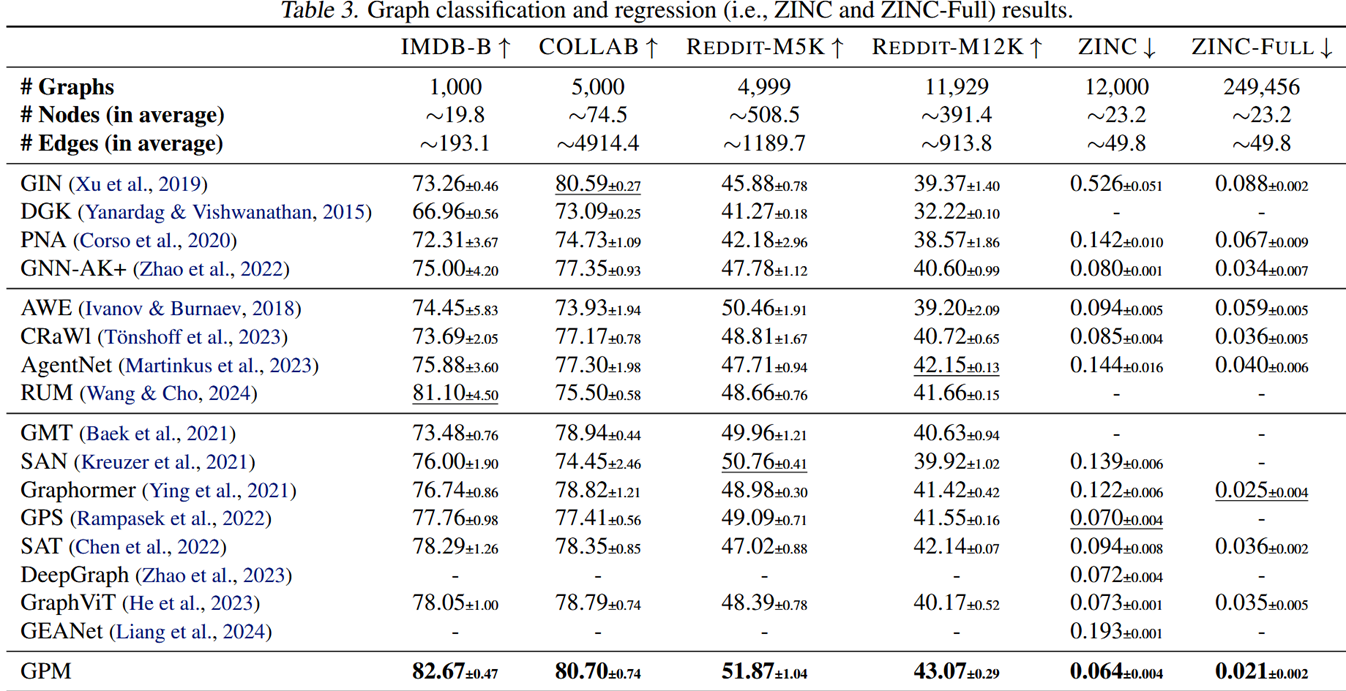
在节点分类、链接预测、图分类/回归等多种任务和数据集上,GPM 系统性优于传统 基于消息传递机制的GNN、基于随机游走的GNN 以及与图 Transformer。
2.突破消息传递,以及GNN过压缩问题的表达能力限制
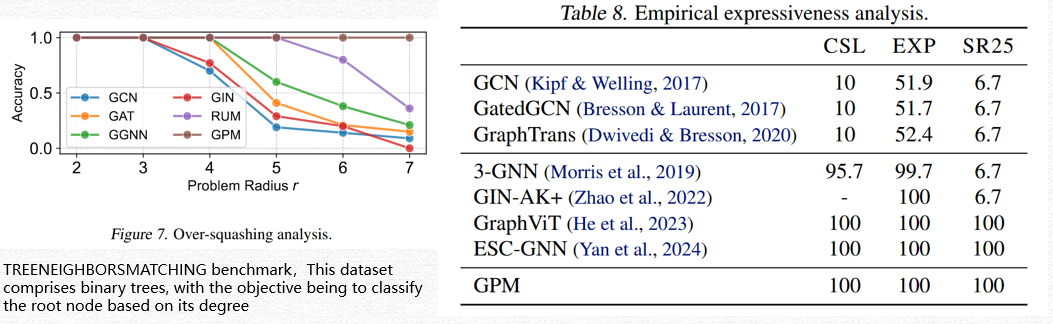
模型能够区分传统 GNN 无法区分的非同构图,验证其更强的理论表达能力,同时也证明GPM模型没有传统GNN的随着层数加深面临的过压缩问题。
3.在高参数模型与 OOD 场景下更稳定
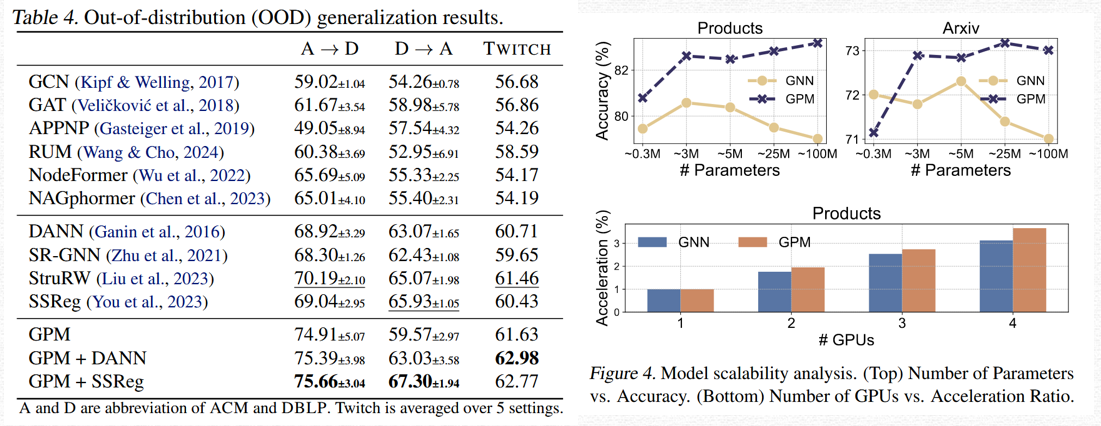
在模型规模增大稳定性测试和分布外测试中,GPM 表现出更好的鲁棒性与泛化能力。
4.具备更好的可解释性
注意力机制能够定位哪些结构模式(如环、三角形)主导预测结果。
5.消融实验
消融实验证明匿名路径的加入是有效的,同时表明位置编码可有可无,同时语义路径编码使用transformer模块是有效的。
五、论文优点与缺陷
优点
- 范式级创新:首次系统性提出“非消息传递”的图学习框架
- 问题导向明确:实验直接回应 message passing 的核心瓶颈
- 性能 + 可解释性兼顾
- 对后续研究具有启发性
缺陷 / 局限
- 对随机采样模式质量依赖较强
- 模型结构相对复杂,计算与工程成本偏高
- 尚未完全解决大规模图上的效率与部署问题
六、总结
本文提出了一种以图结构模式为核心的图表示学习新范式,在理论表达能力、实验性能和泛化性上均显著优于传统消息传递 GNN。该工作表明,图学习不必局限于 message passing,为后续pattern-based graph learning 和新一代图基础模型奠定了重要基础。
Enjoy every single day