GraphCodeBERT: Pre-training Code Representations with Data Flow(ICLR 2021)
论文链接:[2009.08366] GraphCodeBERT: Pre-training Code Representations with Data Flow
模型开源链接:microsoft/graphcodebert-base · Hugging Face
摘要
本文提出 GraphCodeBERT,一种将程序数据流结构融入预训练的代码理解模型。与只关注 token 序列的传统预训练方法不同,该模型显式建模变量依赖关系,并通过结构引导的掩码预测与对齐任务增强语义学习能力。实验结果表明,GraphCodeBERT 在代码搜索、克隆检测、转化与修复等多项任务上均取得显著提升,说明数据流结构能有效增强代码语义建模。
数据集介绍
论文使用 CodeSearchNet 数据集进行预训练与评估,包含约 2.3M 对自然语言描述与代码样例,覆盖 Python、Java、JavaScript、Ruby、Go、PHP 六种语言。这里我们已经详细介绍过了,详见:论文日常阅读笔记——CodeSearchNet 2019 – 个人计算机算法学习分享
下游任务评估涉及多个公开数据集:
- 代码搜索:多语言检索任务(MRR评价)
- 程序克隆检测:BigCloneBench(F1评价)
- 代码翻译:Java↔C# 翻译任务(BLEU评价)
- 缺陷修复:Defects4J 数据集(Accuracy)
数据规模大、任务种类多,有助于验证预训练模型的鲁棒性与普适性。
模型构造与训练方法
GraphCodeBERT 的核心思想是 将数据流图与代码 token 共同输入 Transformer,并让预训练任务感知结构信息。
模型结构示意图:
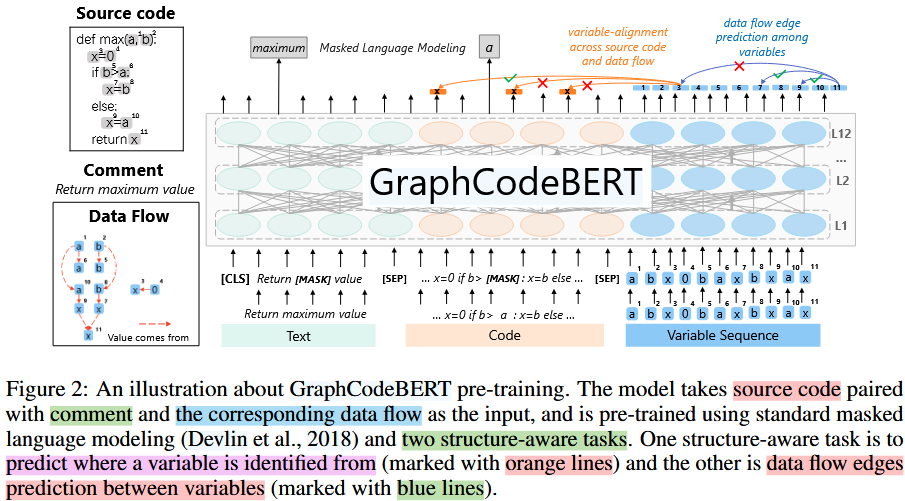
1.模型构造
对于模型构造部分,我们将从输入构造,模型框架两个部分来说明,首先我们先讨论输入序列的构造。
从源代码中提取变量定义与使用之间的 数据流图(Data Flow Graph, DFG),首先我们需要先通过tree-sitter工具构建AST图,然后从AST图中抽取变量及其关系构成数据流图。
图构建流程示意图:
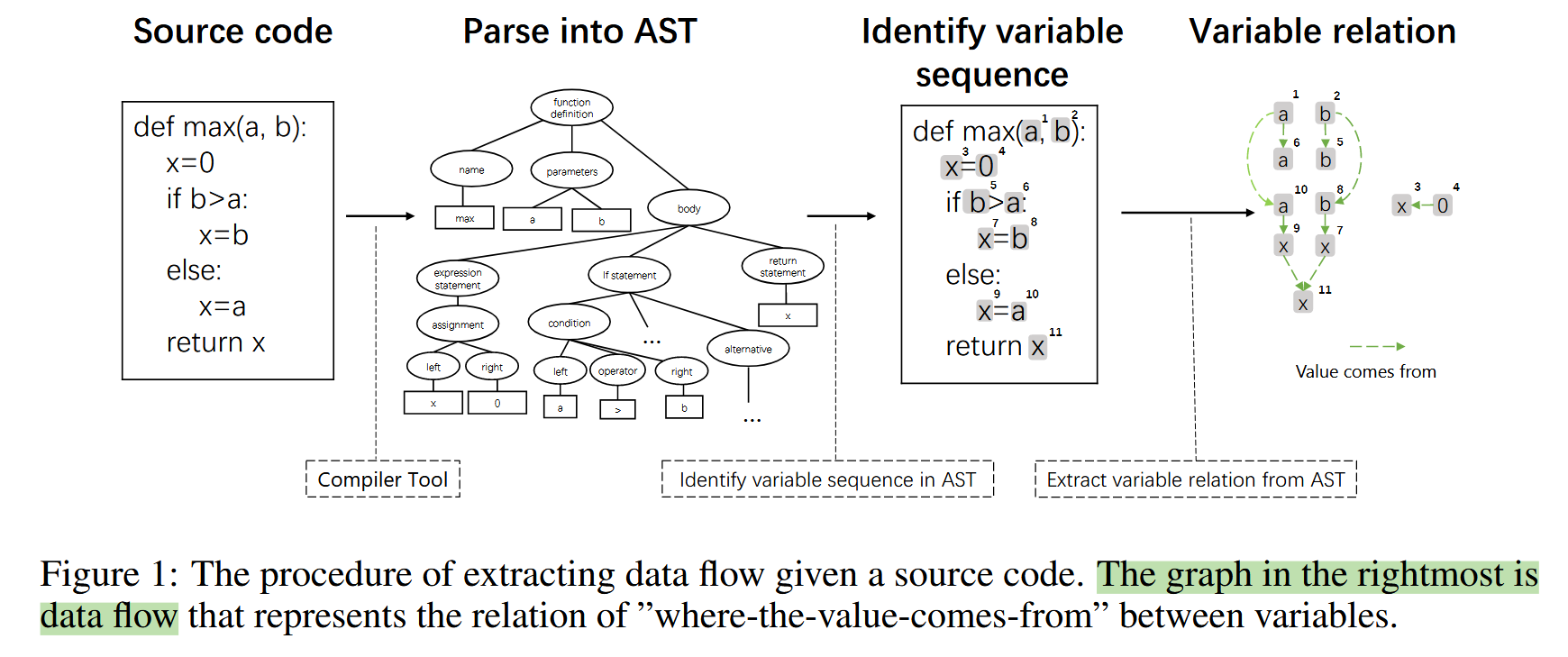
最后将对于
注释—代码—数据流节点
构建
X = {[CLS], W, [SEP ], C, [SEP ], V }
其中W={w1,w2,w3,....}为代码注释token
C={c1,c2,c3,.....}为代码片段token
V={v1,v2,v3......}为数据流节点token
同时我们保留V间的关系以及C与V间的变量来源关系,其中边的关系具体保存在边注意力矩阵中。接着我们将这个融合了代码数据流结构的序列作为模型输入。
接着graphcodebert将使用和codebert一样的词表BPE(Byte-Pair Encoding),将其中每个token转化为向量+位置向量以得到每个输入向量Hi。
接着模型的核心结构是12个transformer层,结合多头注意力机制:
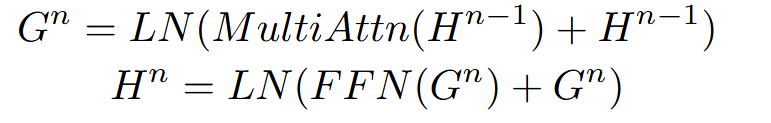
其中为了利用图结构特点,我们在多头注意力中引入了图引导注意力(Masked Graph-guided Attention)
限制某些注意力只能够访问语义相关节点,例如通过mask矩阵使得每个数据流节点/代码token只能关注与其有直接连接边的数据流节点/代码token(v与v,v与c),其中边关系体现在注意力矩阵M中:
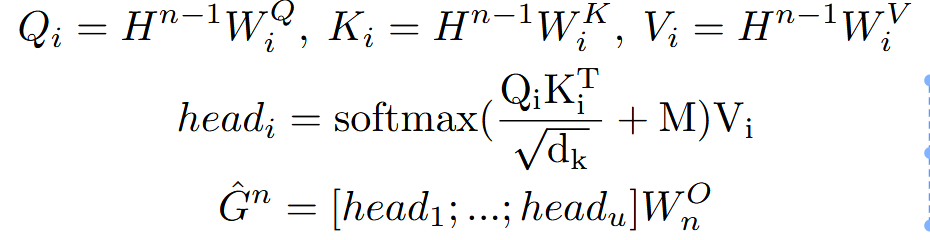
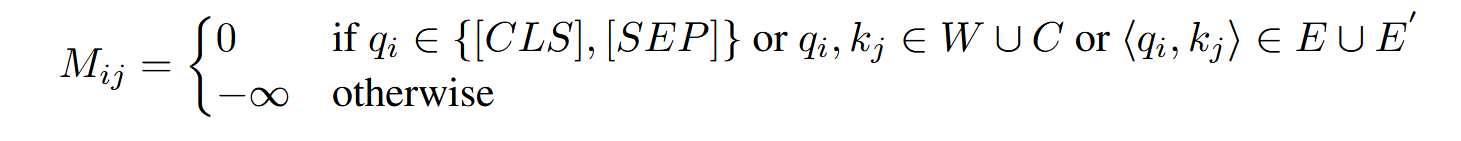
2.三个结构增强预训练任务
其实训练任务本质上就是从某种角度建模,使用数学公式定量表示量化对于角度能力,然后通过梯度下降过程使得模型提升对应角度的量化数值。
-
MLM(掩码语言模型):
这里论文原文中将注释和代码token随机采样其中的15%mask掉,然后选择其中的80%将其用【mask】代替,5%使用随机token取代,15%不变
接下来使用模型来预测填补缺失代码/文本 token对应的嵌入向量,接着将这个嵌入向量喂给分类器,最后让预测生成的对应已经训练好的分类器中正确token对应概率尽可能大。
-
结构边预测(Edge Prediction):预测变量之间的依赖关系,这里注意是预测输入序列X中的V(数据流节点)部分内部的边预测。
论文中具体的处理方法是在X的V token部分中随机采样20%,然后将直接与被采样的边mask掉(将其图注意力矩阵对应位置加上负无穷),接着我们通过将两点之间存在边关系的概率数学量化为
Pij = sigmoid(HixHj)
对应损失函数定义为:
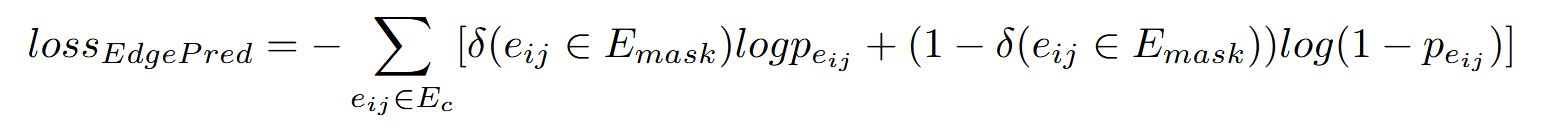
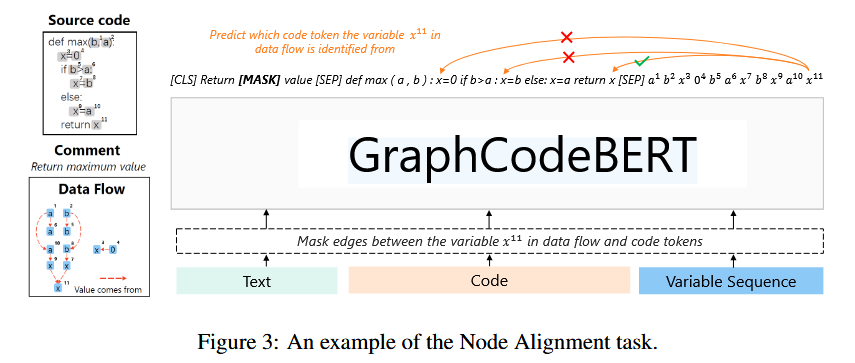
- 变量节点对齐(Node Alignment):将数据流节点与其代码位置对齐,其底层原理和结构边预测相似,只是变量节点对齐是在C(代码token)和V(数据流token)间进行的。这里就不详细介绍了。
节点对齐任务示意图:
这一组合使模型不只“看见字符”,而是真正理解变量含义、语义依赖与执行逻辑。
实验结果
| 任务 | 对比模型 | 改进幅度 | 意义 |
|---|---|---|---|
| 代码搜索 | vs. CodeBERT | MRR提升约 2–3% | 更准确检索语义相关代码 |
| 克隆检测 | vs. GraphNN/CodeBERT | F1 提升显著 | 更好捕捉语义相似结构 |
| 代码翻译 | vs. Seq2Seq/Transformer | BLEU 提升 | 更准确把握变量语义 |
| 缺陷修复 | 对比T5/BERT模型 | Accuracy提升 | 更精准定位语义错误 |
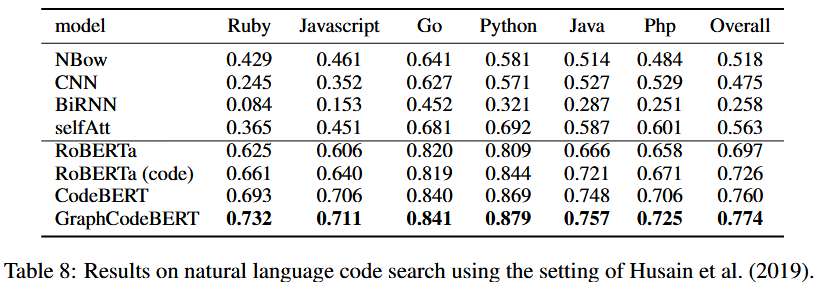
codesearchnet挑战赛任务结果:
消融实验部分(评估参数MRR,候选集由挑战赛的1000个候选查询集拓展到整个语料库):
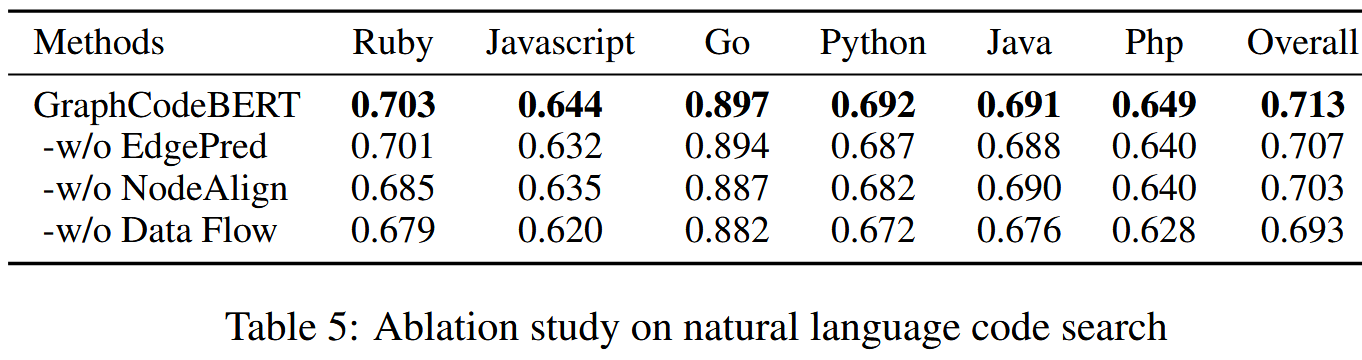
研究还显示,模型在推理阶段明显关注数据流节点,说明结构并非辅助信息,而是语义理解的核心依据,同时还表明数据流图的效果优于AST图。
论文优点与缺陷
优点
- 提出数据流增强预训练的新范式,理论与实验均证明结构对代码理解的必要性。
- 结构与序列深度融合,不是简单拼接,而是真正改变注意力机制。
- 跨任务、跨语言验证性能领先,具有强泛化性与实用价值(对软件工程工具意义重大)。
缺陷
- 依赖静态分析工具提取数据流,对动态语言(如 JS、Python)或不完整代码表现不稳定。
- 结构提取成本高,在工业规模(大型仓库、自动化构建)下存在扩展性问题。
- 无法很好处理动态行为(运行时反射、动态类型、隐式依赖等),仍无法覆盖真实复杂语义。
总结
GraphCodeBERT 通过在预训练中引入数据流结构,使模型不再仅依赖代码 token 序列,而能够显式理解变量依赖和语义逻辑。我个人感觉这个是通过人类直觉逻辑绑定各个token的相关关系,再利用特定方向的损失函数的量化和设置,最后再训练中完成类似于注意力机制的token对齐机制。
实验结果表明,这种结构增强的预训练方式在多项代码理解与生成任务中显著提升性能,证明语义结构是构建代码智能模型的关键。尽管方法受限于静态分析与结构提取成本,但其提出的“结构感知预训练范式”对代码语言模型的发展具有重要推动作用,为未来面向真实软件场景的代码智能研究提供了新的方向。


https://shorturl.fm/g7Mza