Deep Graph Matching and Searching for Semantic Code Retrieval(TKDD 2021)
论文链接:https://doi.org/10.1145/3447571
开源仓库地址:https://github.com/ryderling/DGMS
摘要(核心思想)
论文聚焦于自然语言到代码的语义检索问题,提出了一个新的深度图匹配模型 DGMS(Deep Graph Matching and Searching)。
核心想法是:将自然语言描述与代码片段统一建模为图结构,并通过图神经网络和跨图交叉注意力机制对两者进行细粒度对齐,从而学习更准确的跨模态语义表示。该方法在多个基准数据集上显著超越现有深度学习模型,证明结构化图表示对于代码理解极为重要。
数据集介绍
论文使用两个公开的数据集进行代码检索实验:
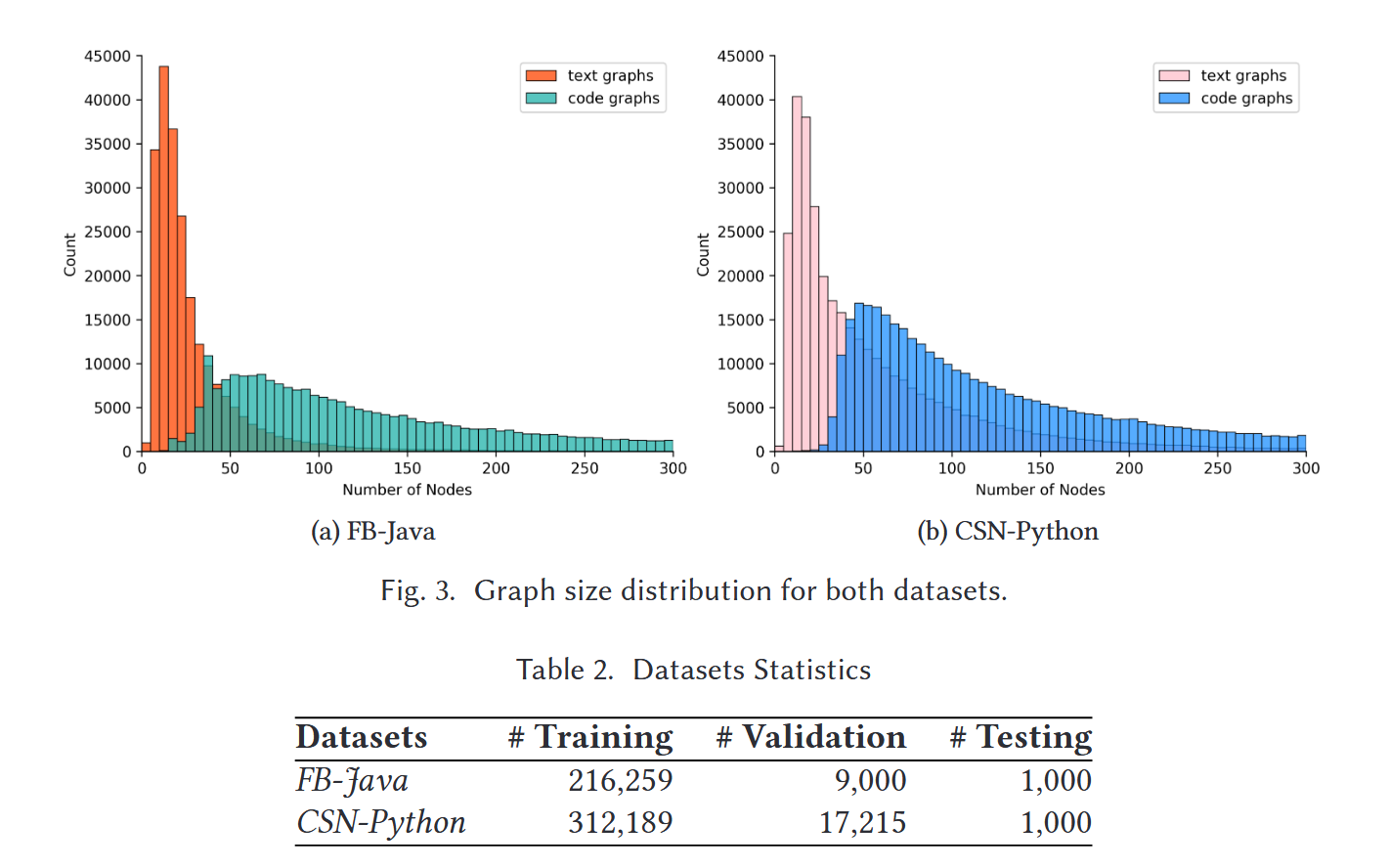
1. FB-Java
- 来源:Facebook研究团队用该数据集评估神经代码搜索模型的性能(目前已经移除了)
- 语言:Java
- 规模:处理得到249072对源代码-文档描述数据集
- 特点:
- 真实开发场景中自然语言描述质量高
- 用途:测试模型对真实描述 → 代码匹配的能力
2. CodeSearchNet 部分数据(CSN-Python)
- 包含更多方法级代码片段
- 语言:Python
- 规模:处理得到364891对源代码-文档描述数据集
- 用途:补充验证泛化能力
所有数据都采用自然语言查询、代码候选库的检索任务形式。
模型构造与训练方法
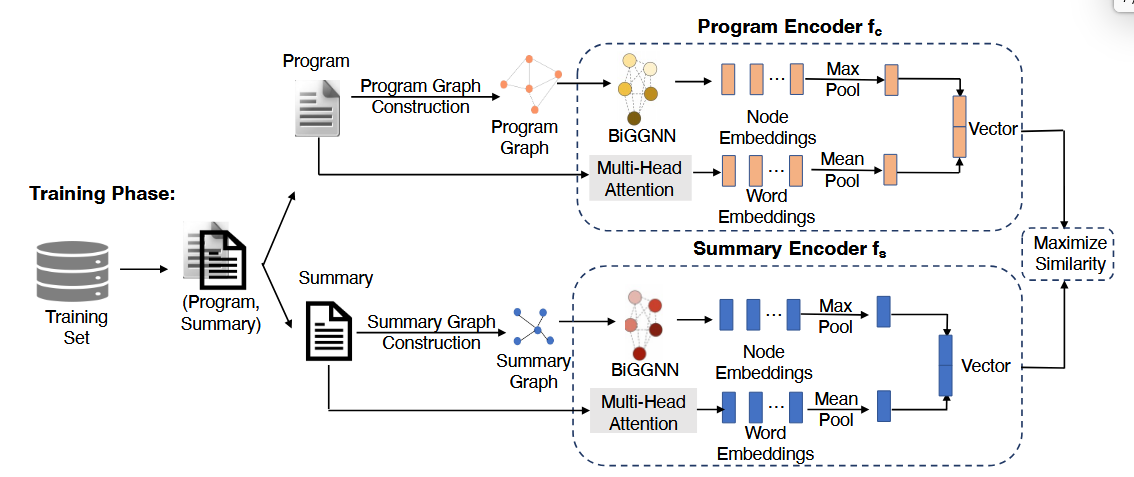
构图示例:
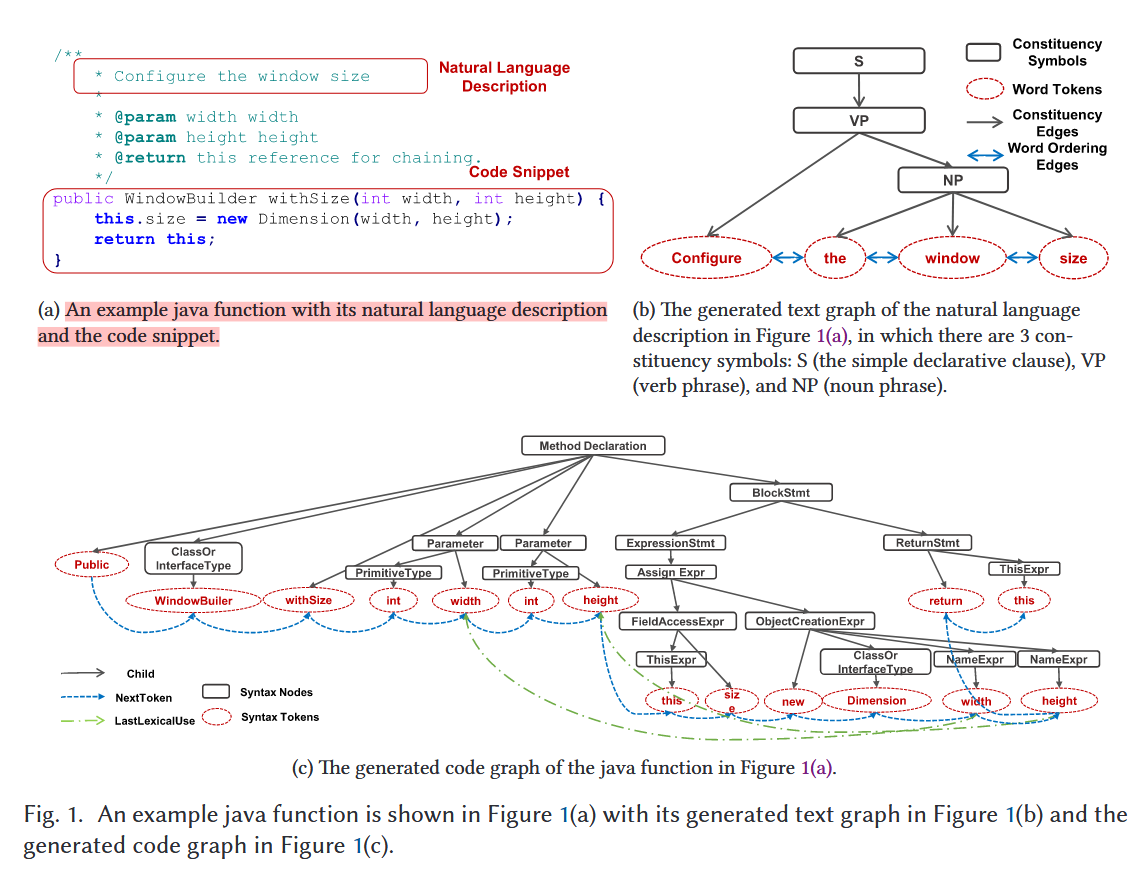
1. 图构建(Graph Construction)
论文将文本和代码分别转换成图:
- 文本图(Text Graph):由 constituency tree + 顺序关系构成(工具:
Stanford CoreNLP toolkit) - 代码图(Code Graph):由 AST + token 顺序 + 数据/控制依赖构成
目的:表达结构与语义关系。
2. 图神经网络编码(Graph Encoding)
本文采用 R-GCN(Relational GCN)对文本图与代码图分别编码,获得两个图中每个节点的语义向量。这里各节点初始化编码的方法是利用GloVe直接生成,由于每个节点本身是一个word token,这里的处理可以利用预训练好的模型来进行编码。
如果遇到了词表里不存在的词我们则需要将这个词划分为subtoken再编码,最后所有subtoken编号的平均值作为这个新词的编码。
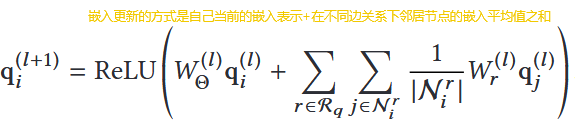
3. 跨图语义匹配(Graph Matching)——模型核心
模型示例图:
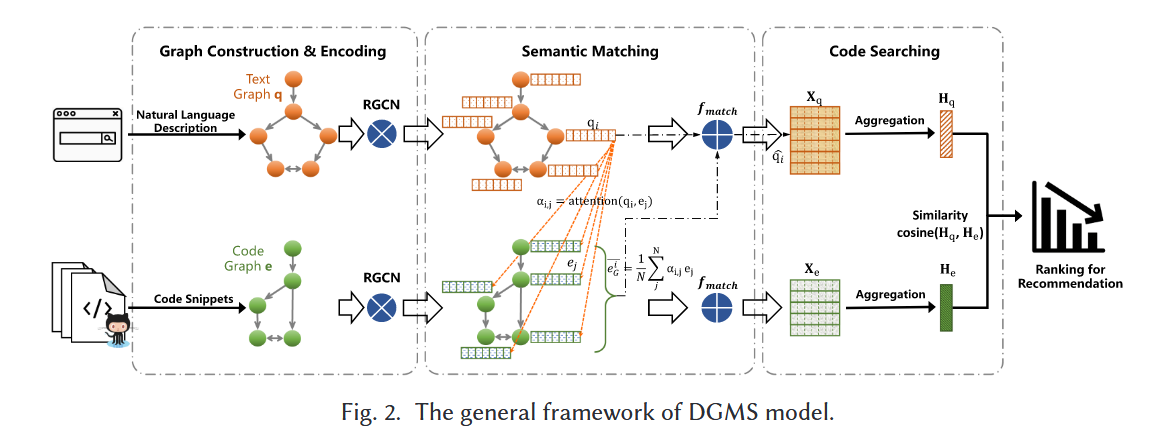
论文的关键创新点是跨图节点级的对齐机制:
对文本图中每个节点:
1.计算与代码图和文本图各自每个节点编码后向量的相似度
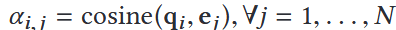
2.然后聚合得到该节点在另一个图的“代码语义上下文”
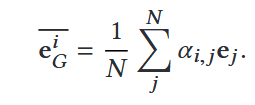
3.使用 Sub + Mul 方式进行跨模态特征融合(mul的乘法是逐项相乘)
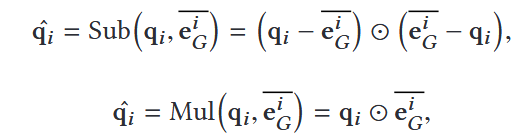
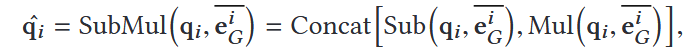
4.多层迭代更新文本节点表示
此过程模拟了“自然语言描述的成分 ↔ 代码结构组件”的对应关系。
4. 图级表示与相似度
- 对于每个图(代码图、文本图)的所有节点嵌入向量使用 FC + Max Pooling 汇聚节点表示,对文本图和代码图生成最终图向量
- 使用 cosine similarity 判断匹配程度
5. 训练方式
损失函数定义:
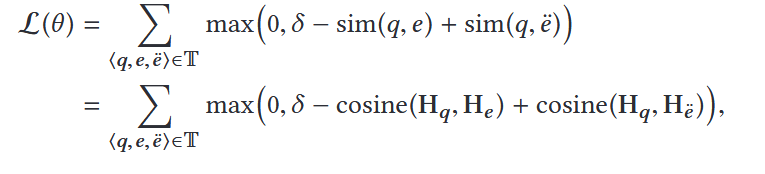
采用三元组损失(Triplet Ranking Loss):
在构建训练集的时候,我们通过将文本描述片段+代码片段+随机代码片段构建成为一个三元组,通过对比学习,我们让正确代码-文本对的得分高于错误代码-文本对的得分即可达到模型收敛学习的效果。
实验结果
评判指标:mean reciprocal rank (MRR) and success at k (S@k)

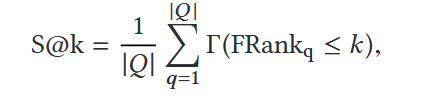
1. 在 Python 和 Java 两个数据集上均大幅领先现有方法
尤其是 Python 数据集中:
- MRR 提升最高达 22%
- Top-1 提升接近 28%
证明 DGMS 在理解自然语言描述与代码语义方面显著优于序列模型和普通图模型。
2. 消融实验验证 DGMS 的各模块均显著贡献性能
- 去掉图结构 → 性能明显下降
- 去掉跨图匹配(Sub/Mul)→ 性能大幅下降
- FCMax 池化 > Avg/Max 单独池化
说明结构化建模与细粒度对齐是性能提升的原因而非偶然。
3. 与多种 baseline(DeepCS、BiRNN、CodeBERT 变体等)相比均取得最好成绩
表现稳定、提升清晰、有显著统计意义。
论文优点与不足
论文优点
1. 方法创新性强:首次实现自然语言图与代码图的深度跨图匹配。
不仅对每一端编码,还做成分级(component-level)对齐。
2. 结构化表示与跨模态对齐相结合,有明确贡献来源。
消融实验充分证明每个设计决策是有效的。
3. 实验全面、指标领先显著,增强了说服力。
覆盖两个语言、多个 baseline、多个变体。
论文缺陷或潜在局限
1. 图构建过程依赖人工设计与复杂解析器,难以扩展到更多语言。
不同语言的 AST、依赖关系都需要定制。
2. 模型计算成本较高,不利于极大规模代码库上的实时检索。
GNN + cross-graph attention 的复杂度较高。
3. 仅在方法级(function-level)评测,未测试更真实的仓库级检索场景。
函数间依赖、跨文件检索的能力仍未验证。
总结
论文提出 DGMS,一个基于统一图表示和深度跨图匹配的代码检索模型,创新且性能显著提升。
它展示了结构化图建模 + 跨模态对齐在代码理解和软件工程任务中的巨大潜力,同时也暴露出结构构建成本高、计算开销大等工程化挑战。
未来可以探索的点:
1.不同图基础模型对于该模型的优化程度,虽然论文显示该模型对于不同图基础模型的区分度不高
2.对齐机制的向量拼接还可以补充实验,探究真正发挥作用的是哪个部分。
3.如果代码拓展到仓库级别,如何处理?