Code Search Is All You Need? Improving Code Suggestions with Code Search(ICSE 2024)
论文开源仓库链接:https://github.com/iCSawyer/CodeSuggestion
一、摘要
本文系统研究了代码搜索(Code Retrieval)在代码补全与代码生成任务中的作用。作者提出一个统一的检索增强代码建议框架,将相似代码搜索结果作为上下文输入不同类型的代码生成模型(包括传统深度学习模型和大语言模型)。大量实验表明,引入代码搜索可以在不修改模型结构的情况下,显著提升代码建议性能,且在 ChatGPT 等大语言模型上提升尤为明显,证明了检索在 LLM 时代仍具有不可替代的价值。
二、数据集
论文主要使用了公开、广泛使用的代码数据集,覆盖代码补全与代码生成两类任务:
-
代码补全数据集
- 以函数体或代码片段为单位
- 评估 token-level 与 line-level 补全性能
主要是CodeMatcher(Java)、PyTorrent(python)
-
代码生成数据集
- 输入为自然语言描述(如方法注释)
- 输出为完整方法或代码片段
主要是CodeXGLUE
数据集覆盖多个真实软件项目,保证了实验结论在实际开发场景下的代表性。
三、模型构造与训练
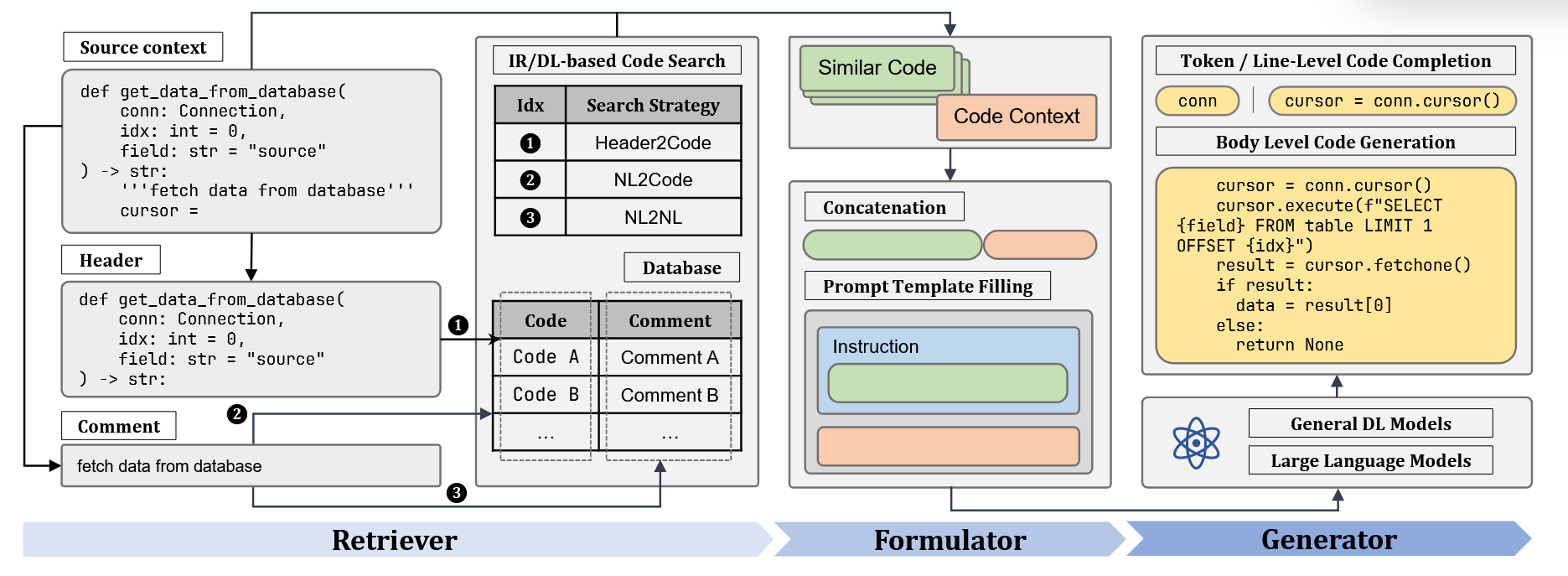
1️⃣ 检索增强总体框架
论文提出一个三阶段统一框架:
-
Retriever(检索器)
- 根据当前代码上下文或自然语言描述
- 检索语义相似的历史代码或注释
- 支持多种策略:
- Header → Code
- NL → Code
- NL → NL
这里的Header代表函数的核心信息,例如:
def is_palindrome(s: str) -> bool: """ Check whether a given string is a palindrome. """ s = s.lower() return s == s[::-1]上面函数的header是:
def is_palindrome(s: str) -> bool -
Formulator(上下文构造)
- 将检索到的示例与当前输入拼接
- 构造成模型可接受的 Prompt 或输入序列
-
Generator(生成器)
- 使用不同模型生成代码,包括:
- LSTM
- Transformer
- ChatGPT(in-context learning)
- 使用不同模型生成代码,包括:
2️⃣ 训练与推理方式
- 非 LLM 模型:常规监督训练
- ChatGPT:不进行微调,仅采用 zero-shot / few-shot Prompt
- 强调:检索增强不依赖重新训练模型
四、实验结果
核心实验发现:
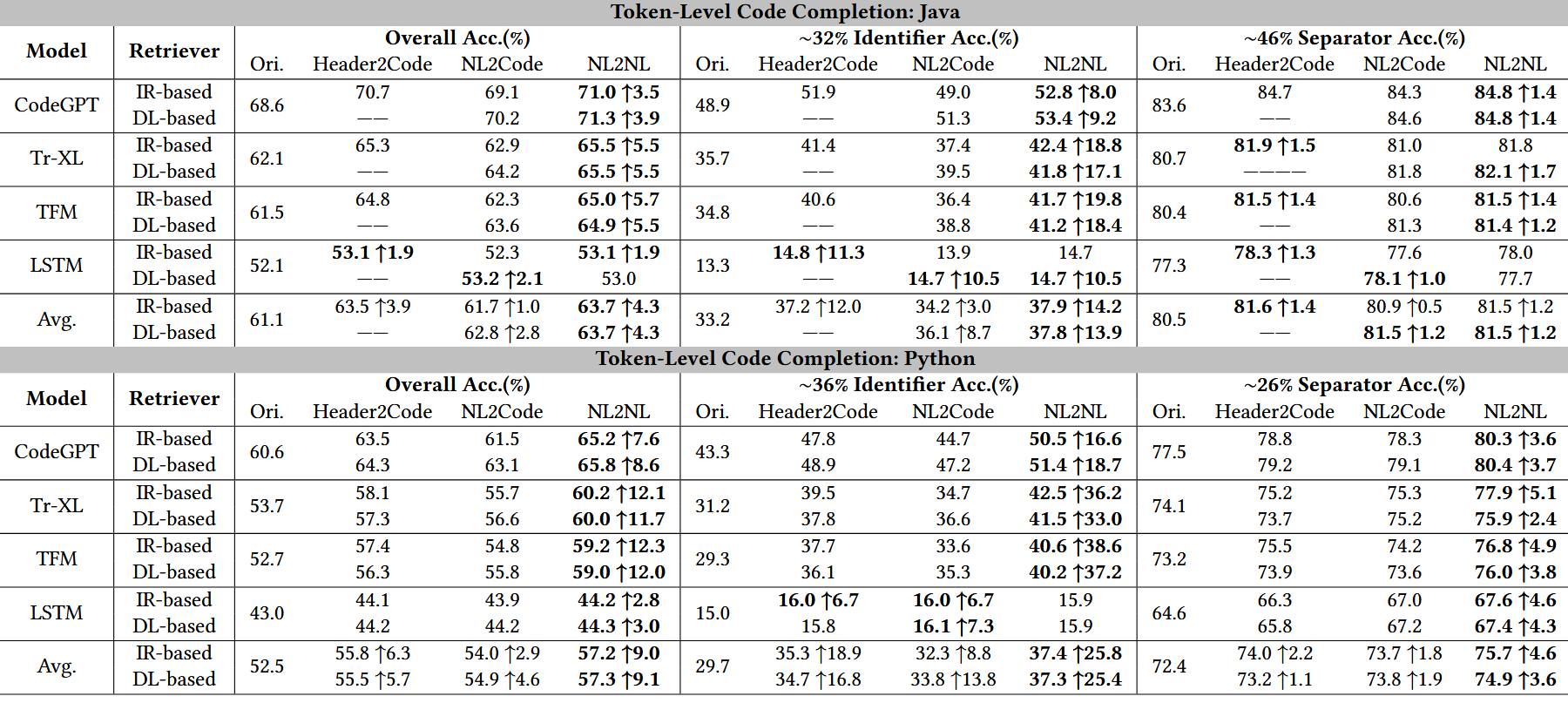
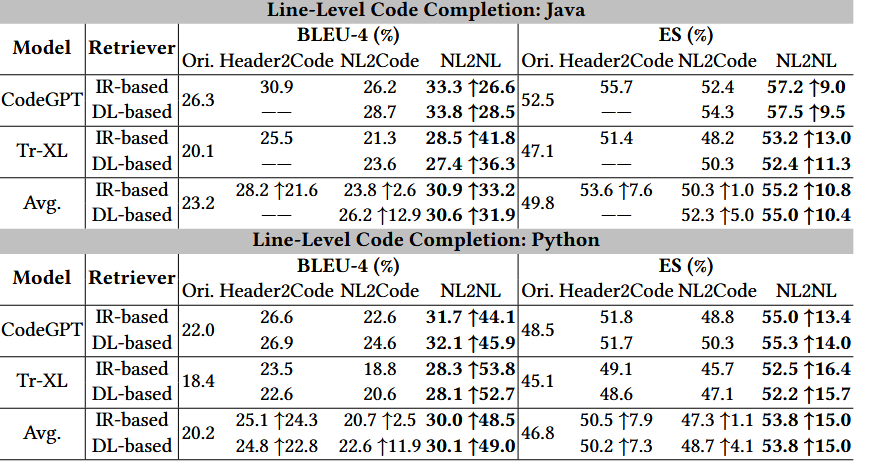
代码补全任务相关实验结果:
代码生成相关实验结果:
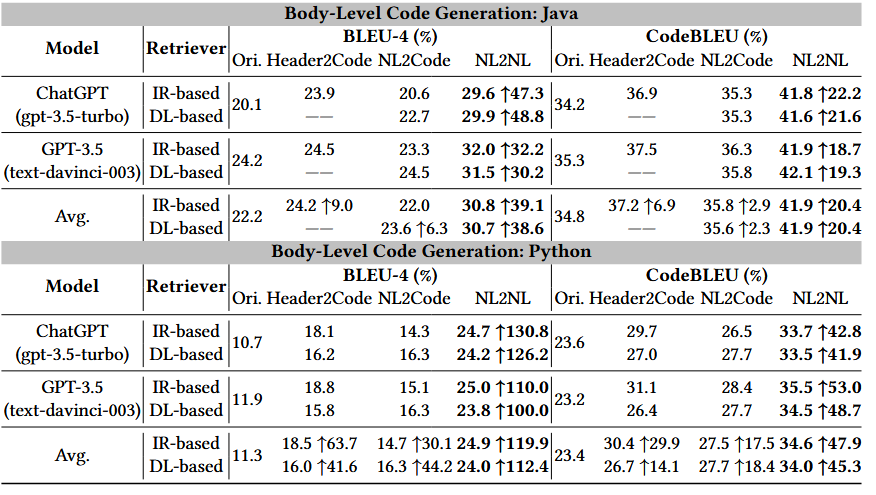
1.检索增强在所有模型上均带来稳定性能提升
-
代码补全与代码生成任务中,BLEU、CodeBLEU 等指标显著提高
2.对 ChatGPT 等大语言模型提升最显著
-
在代码生成任务中,BLEU-4 提升最高可达 130%
-
表明 LLM 依然强烈依赖高质量示例(1 shot即足够)作为上下文参考
3.同模态检索(尤其 NL → NL)效果最佳
- 使用自然语言描述检索相似注释,再提供对应代码
- 比直接检索代码片段更加稳定、鲁棒
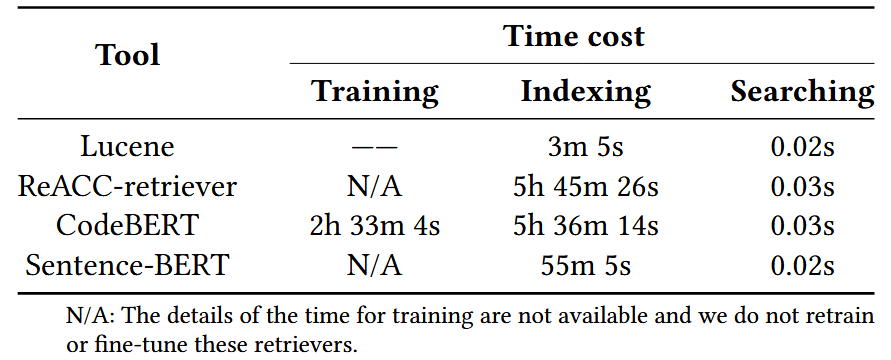
4.IR-based方法和DL-based方法效果相近,但是IR前期构建耗时更短
五、论文优点与缺陷
优点
- 问题贴合真实开发实践(先搜代码、再写代码)
- 方法简单通用,工程可落地性极强
- 实验系统、变量控制充分,结论清晰可信
- 首次系统验证检索在 LLM 时代仍然重要
局限性
- 方法创新主要体现在系统整合,相关idea其实其他人早已经做过了,而且理论机制分析较浅
- 性能依赖于代码库规模与注释质量
- 未利用仓库级结构(调用图、依赖图等更深层信息)
六、总结
本文通过统一的实验框架和大量实证结果,证明了代码搜索是提升代码补全和代码生成性能的关键手段,即使在大语言模型时代依然成立。论文为检索增强代码智能系统提供了模型无关、低成本、高收益的解决方案,也为后续研究在仓库级检索、结构化上下文建模等方向提供了坚实的实验基础。
潜在点:同时实验结果有一点令人在意的部分,即基于IR的方法似乎比基于DL的方法更具有工程实践应用价值,其潜在原因我怀疑是论文选取的数据集中涉及到的检索可能原词检索的比重较大,使得BM25评估效果比神经网络效果更加直接更加好。后续考虑强化数据集,增加同义不同词的检索场景,再验证效果。