RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation(EMNLP 2023)
论文链接:[2303.12570] RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation
开源代码仓库: https://github.com/microsoft/CodeT/tree/main/RepoCoder
摘要
该论文研究“仓库级代码补全”问题,即模型在补全代码时不仅依赖当前文件,而能利用整个代码仓库中分散的相关信息。
为解决传统方法无法有效定位仓库内关键代码片段的问题,作者提出 RepoCoder ——一种基于迭代式检索-生成的代码补全框架,通过让模型的初次补全结果反向指导检索,使检索到的代码片段逐步更接近真实目标,从而显著提升跨文件补全能力。
论文同时构建了 RepoEval 基准数据集(涵盖行级、API 调用、函数体等三类任务),并在多种模型上验证方法有效性。
数据集介绍
作者指出现有数据集无法系统评估“仓库级补全”能力,因此构建了 RepoEval,特性包括:
(1) 数据来源
- 选取 2022 年之后的高质量 GitHub 仓库
- 满足:开源协议、非 fork、>100 star、Python 占比 >80%、包含单元测试
(2) 三类任务场景
- 行级补全(Line Completion)
从 8 个仓库中各抽取 200 行,共 1600 样本。 - API 调用补全(API Invocation)
抽取仓库内部 API 调用示例,共 1600 样本。 - 函数体补全(Function Body Completion)
从较小且可运行的仓库中抽取 373 个函数体,并通过原仓库单元测试评估。
(3) 特点
- 使用真实项目代码
- 评估指标全面(EM、ES、Unit Test Pass)
- 能评估“可执行正确性”而不仅是文本相似度
模型构造与训练
RepoCoder 不需要额外训练,完全基于预训练模型+检索器组合,核心为:
3.1 整体框架:迭代式检索-生成
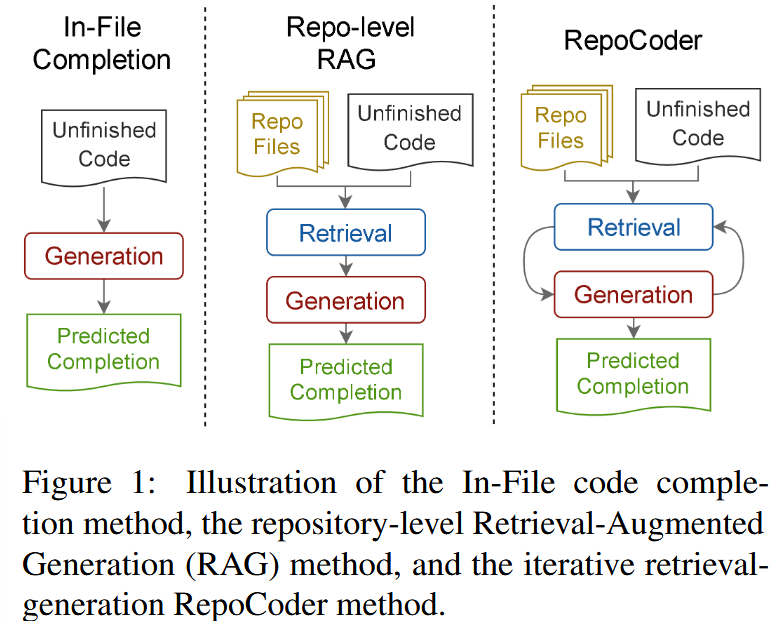
步骤 1:建立代码片段数据库
将仓库代码以滑动窗口切分为片段,用于检索。
步骤 2:初次检索(基于未完成代码)
利用 unfinished code X 作为检索 query,从仓库取出最相关片段。
步骤 3:生成初次补全
将“检索得到的片段 + 当前文件内容”一起喂给预训练模型 M 生成补全 Ŷ₁。
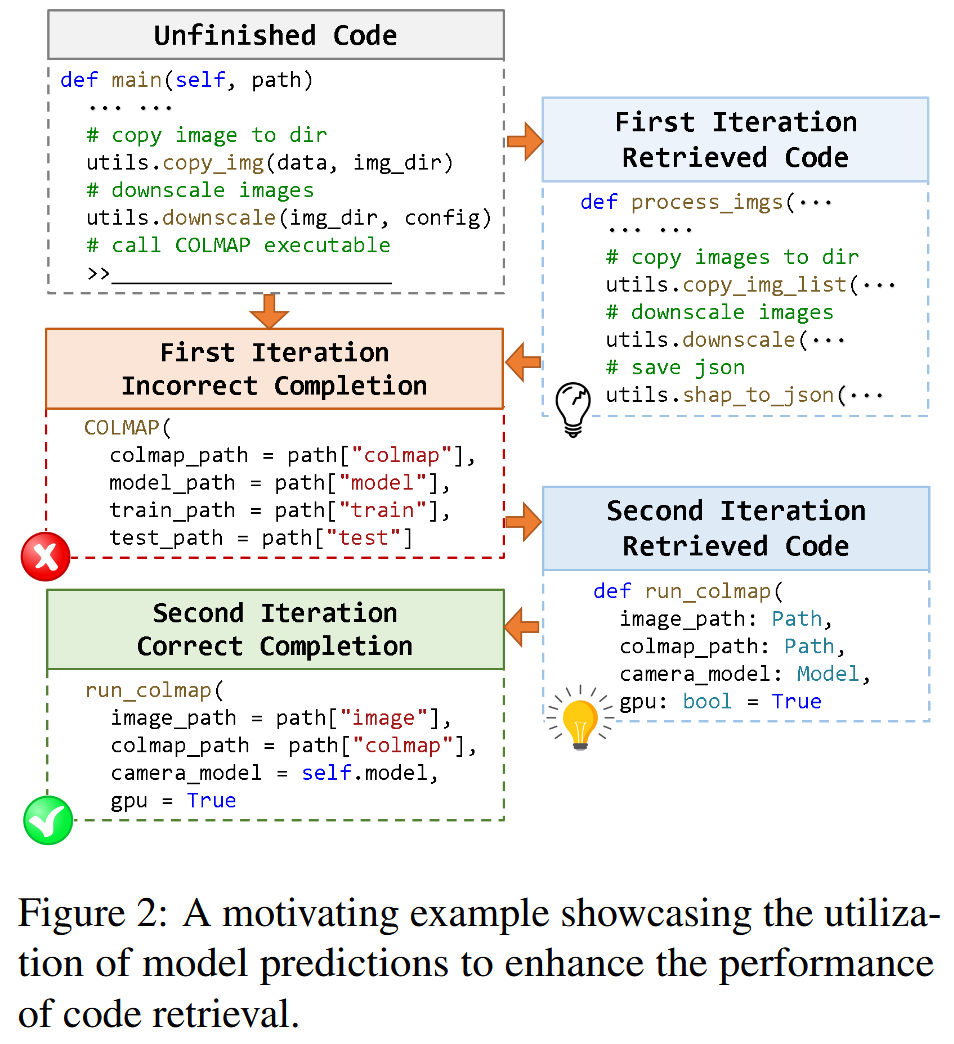
步骤 4:基于生成结果进行第二次检索(核心创新)
使用 X 与 Ŷ₁ 的部分内容构造新查询,重新检索代码片段,从而获得更接近目标的片段。
步骤 5:再次生成补全,可循环多轮
这一“生成辅助检索→检索辅助生成”的闭环是该方法最大亮点。
具体流程样例图:
3.2 组件说明
- 检索器:Jaccard-based sparse retriever(也尝试过 UniXcoder dense retriever,效果相近)
- 生成模型:GPT-3.5、CodeGen 6B/2B/350M
- 无需训练:完全基于 prompt engineering + 检索逻辑构造
实验结果
4.1 仓库级补全大幅提升补全性能
与 In-File(仅看当前文件)相比:
- Exact Match 提升 > 10%
- Edit Similarity 提升约 8%
- 效果跨不同模型尺寸均一致
证明仓库级信息是有效的且可被方法成功利用。
4.2 迭代式检索优于传统单轮 RAG
2 轮 RepoCoder consistently outperform 单轮 RAG
表明“生成→辅助检索→再生成”的循环真正提升检索质量。
4.3 函数体补全可运行正确率明显提升
在 unit tests 评估下:
- RepoCoder 显著优于 In-File
- 接近 Oracle(使用真实 ground-truth 检索线索的上限)
说明 RepoCoder 不只是文本更像,而是能生成真正可运行的、语义正确的代码。
论文优点与缺陷
5.1 优点
(1) 方法简单、高效、无需训练,却带来显著提升
迭代式检索-生成是一个“投入极低 → 提升显著”的创新。
(2) 首次系统性提出并解决仓库级补全任务
明确问题定义 + 构建高质量 benchmark,对领域意义重大。
(3) 实验可靠、广泛、跨模型一致
从轻量模型到 GPT-3.5 都受益,证明框架普适性强。
5.2 潜在局限性
(1) 效果依赖仓库中存在可检索的相似代码
在低重复度仓库中增益有限。
(2) 多轮迭代不完全稳定,最佳轮数难以自动判断
可能出现“迭代越多反而变差”的情况。
(3) 实际部署存在速度和成本压力
多次检索 + 多次调用 LLM 不适合实时 IDE 场景。
总结
RepoCoder 通过简单的“生成辅助检索”循环,有效解决了跨文件代码补全难题,并首次建立了可复现的仓库级补全评测体系,对代码智能领域具有重要推动作用。