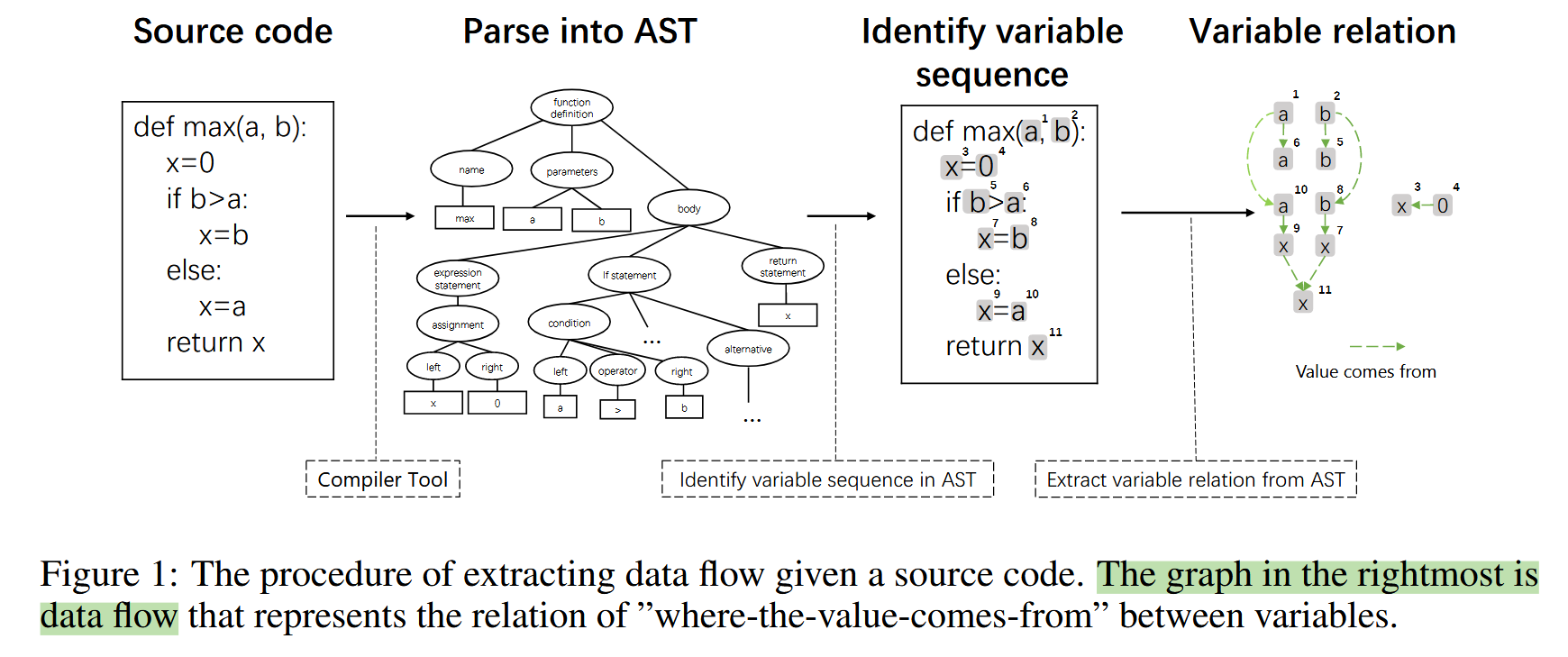
Learning and Evaluating Contextual Embedding of Source Code (ICML 2020)

论文来源:Learning and Evaluating Contextual Embedding of Source Code
开源代码仓库:google-research/cubert at master · google-research/google-research
摘要
这篇论文提出了 CuBERT(Code understanding bert) —— 一个基于 BERT 的大规模代码预训练模型,旨在学习 源代码的上下文语义表示(contextual embeddings),并系统评估其在多项程序理解任务上的效果。
论文构建了一个包含 7.4M Python 文件的大规模语料库,使用 BERT-Large 对其进行预训练,并在六类代码理解任务上验证模型性能。实验结果显示:预训练的上下文表示显著优于从零训练的模型和传统词向量方法,并且在复杂任务(如变量误用定位与修复)中达到 SOTA。
数据集介绍
1. 预训练语料(Pre-training Corpus)
- 来源:GitHub 公共 Python 仓库(hosted on Google’s BigQuery platform)
- 数据量:7.4M Python 文件(9.3B tokens)
- 处理过程:
- 去重(避免代码重复导致过拟合)
- 使用 SubwordTextEncoder 构建约 50K 的子词词表
- 清洗无效或过短文件
该语料用于无监督 MLM 预训练。
2. 微调任务语料库(fine-tuning corpus)
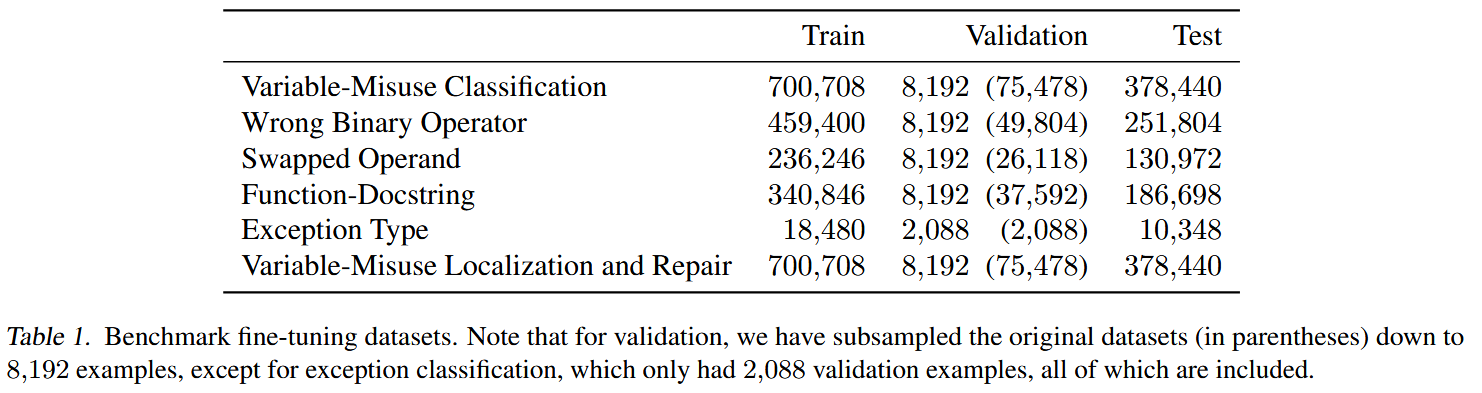
- 来源:使用ETH Py150 corpus来生成对应微调任务的数据集
- 数据量: 约125K Python文件
- 处理过程:
- 去重(避免代码重复导致过拟合)从150K个来着github仓库代码中过滤
- 清洗无效或没有合适license的仓库文件
3. 下游任务(6 个 benchmark 程序理解任务)
| 任务 | 简要说明 |
|---|---|
| Variable Misuse Detection | 判断函数中是否存在变量误用 |
| Wrong Binary Operator Detection | 检测表达式中的运算符是否错误 |
| Swapped Operand Detection | 检测非交换性运算符的操作数是否被错误交换 |
| Docstring–Function Matching | 文档与函数实现是否一致 |
| Exception Type Prediction | 预测代码运行时可能抛出的异常类型 |
| Variable Misuse Localization & Repair | 找出变量误用位置 & 预测正确变量(pointer network) |
这些任务覆盖代码语义理解、控制流推理、文档一致性等多方面能力。
模型构造与训练(CuBERT)
1. 模型结构
- CuBERT = BERT-Large(24 layers)
- 输入序列中可以混合自然语言(docstring)和代码 token
- 使用 ~50K subword vocabulary 覆盖 Python 标识符
2. 预训练任务(Pre-training Objectives)
使用与 BERT 相同的两大任务:
(1) Masked Language Model (MLM)
- 随机 mask 15% token
- 让模型预测被遮住的 token
- 在代码场景中可迫使模型学习变量作用域、类型约束、操作符语义等
(2) Next Sentence Prediction (NSP)
- 判断两个代码片段是否相邻
- 适用于代码结构理解(如函数体、表达式块等)
3. 微调(Fine-tuning)
- 针对 6 个程序理解任务分别构建分类/指针预测网络
- 训练输入可包含整个函数(长上下文)
- 针对长 context size 做了系统分析(32 → 512 → 1024)
实验结果
1. CuBERT 在所有任务上显著优于传统模型
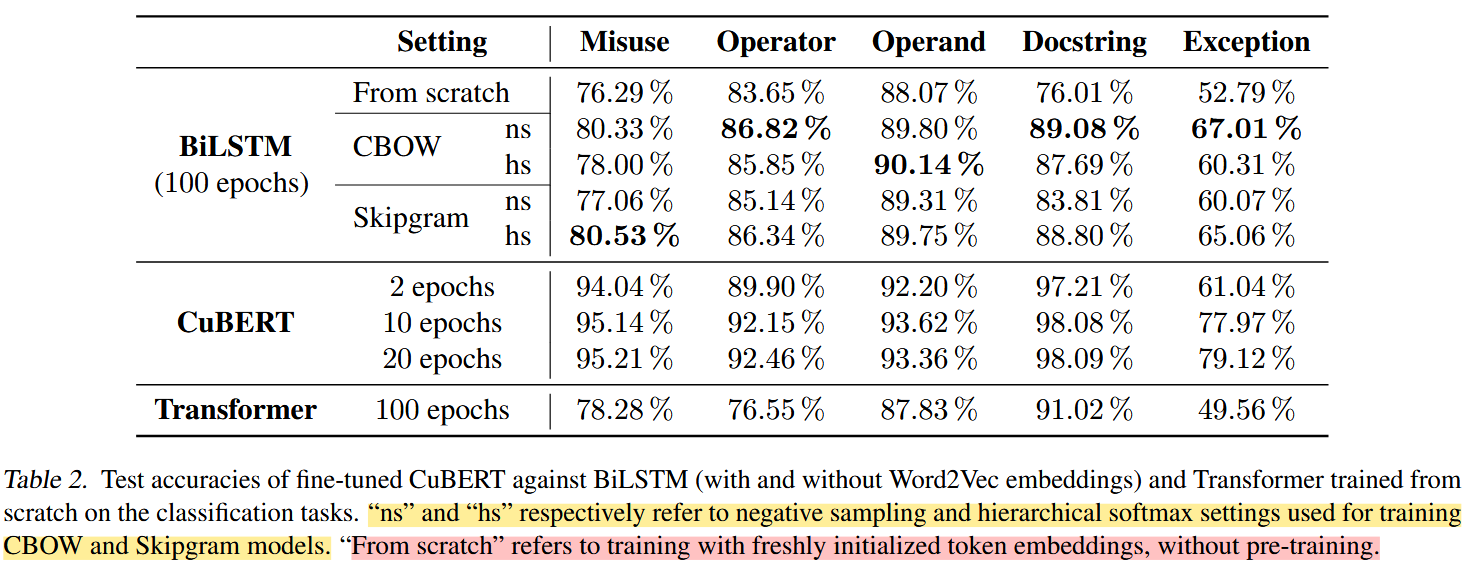
对比包括:
- BiLSTM + Word2Vec
- Transformer(从零训练)
- 图结构模型(基于 AST/CFG/Data-flow)
结果表明:
CuBERT 在五个分类任务上提升 3.2%–14.7%,整体达到新 SOTA。
2. CuBERT 对标注数据需求显著减少
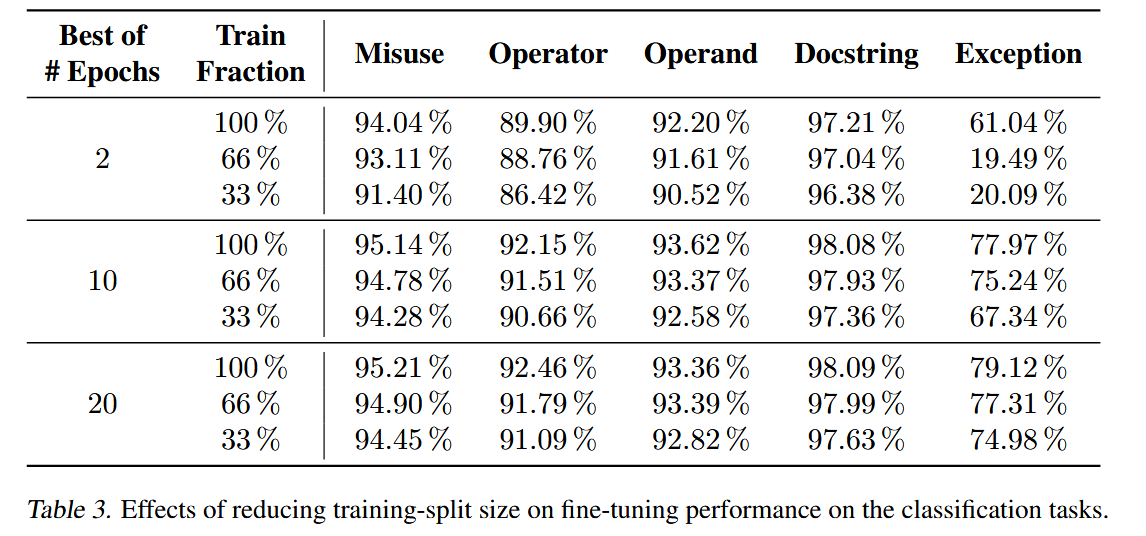
用 33% 训练数据 仍能达到或超过 baseline 模型的效果。
3. 在复杂的 pointer 任务中,CuBERT 显著超越之前的结构化模型
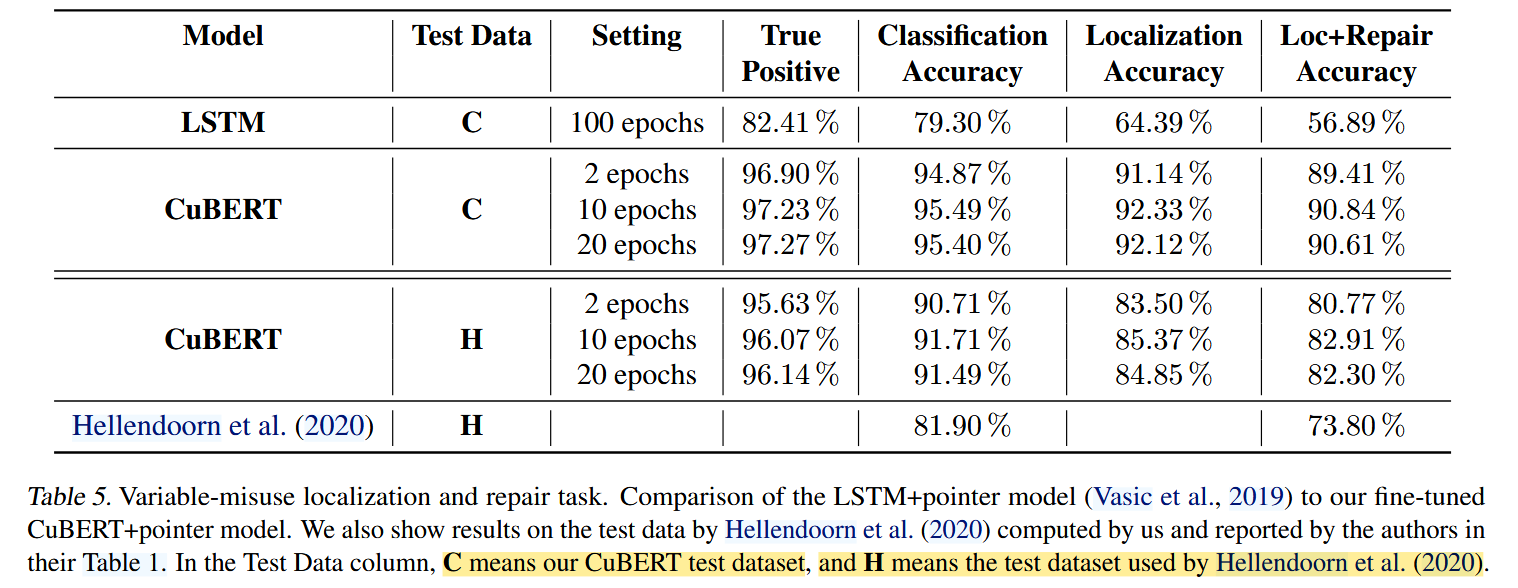
在变量误用的:
- 错误位置定位(bug pointer)
- 正确变量预测(fix pointer)
CuBERT 获得大幅领先,且性能稳定。
4. 更长的 context size 明显提升模型性能
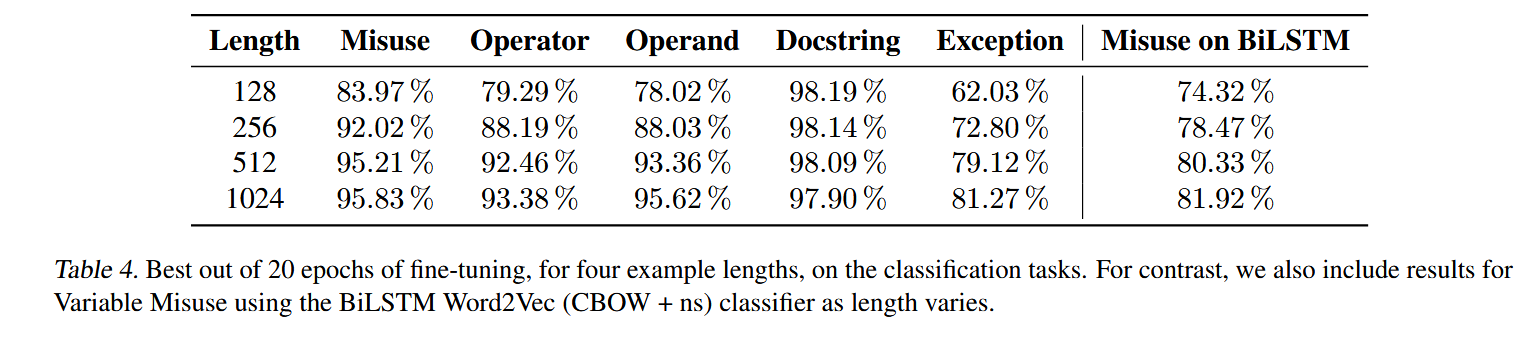
证明代码理解任务非常依赖长距离语义(如变量定义与使用距离远)。
但是同时也发现对应DOCS-CODE查询任务结果反而会随着上下文窗口增大而下降,作者猜测是因为窗口增加引入了更多无效信息。
论文优点与缺陷
优点(优势)
1. 开创性强:首次系统性证明代码预训练的价值
CuBERT 是 code pre-training 的先驱,为后续 CodeBERT、CodeT5 等奠定基础。
2. 构建统一、可复现的 benchmark
包括语料、代码、任务数据、baseline,极大推动领域发展。
3. 纯 token-level 模型就能超越结构化方法
表明 Transformer 上下文能力足以捕获深层代码语义。
缺陷(局限性)
1. 单一语言(Python),缺乏跨语言验证
相比 CodeBERT、GraphCodeBERT 缺少多语言能力。
2. 未使用结构信息(AST / Data-flow)
在更深层语义任务可能不如代码结构模型高效。
3. 预训练成本巨大(BERT-Large + 海量数据)
普通研究者难以复现完整训练过程。
总结
CuBERT 证明了大规模预训练可以极大提升代码理解能力,是代码语义建模领域的重要基础工作,与后续跨模态模型(如 CodeBERT)形成清晰互补。
同时该论文训练cubert的过程中的预训练阶段和微调阶段的设置也值得参考