CodeSearchNet Challenge Evaluating the State of Semantic Code Search(2019)
前排养眼一下

论文相关信息
论文来源:https://arxiv.org/abs/1909.09436
开源代码仓库:https://github.com/github/CodeSearchNet
摘要
语义代码检索任务即通过自然语言查询相关联的代码片段,成为了自然语言和代码的桥梁。本文为了激励该方向的研究,提出了发布 CodeSearchNet 语料库,并提出 CodeSearchNet 挑战赛。
数据集
CodeSearchNet 语料库: 包含6百万个从开源代码中抽取的函数,包含6种语言,包括Go, Java, JavaScript, PHP, Python, and Ruby。其中2百万个函数我们从其官方文档中自动生成了对应注释。便于我们将注释的嵌入层和对应代码的嵌入层训练映射到相同的分布空间。
生成注释文档的方式:将对应函数的文档描述截断仅保留第一段,同时去除对应传参和返回值的深入描述,使得保留的注释类似于查询的要求语句。同时要求对应保留的文档描述token数不小于3
CodeSearchNet 挑战赛:该挑战赛由 99 个自然语言查询组成,其中包含 CodeSearchNet 语料库中可能结果的大约 4k 专家相关性注释。人工专家标注了这4k个相关度注释。这样我们可以用我们训练的模型使用这99个自然语言在这4k个标注的数据上检索,并且根据人工标注的结果给模型打分。
公开榜单需要提交模型weight和bias,结果通过计算模型在6种不同语言上的 NDCG Score,最后求平均值排序。
模型训练
这里作者将每种自然语言(中文,英文)和每种程序语言(python,php…)分布分配一个encoder,然后通过训练让他们映射到相同的联合向量空间。
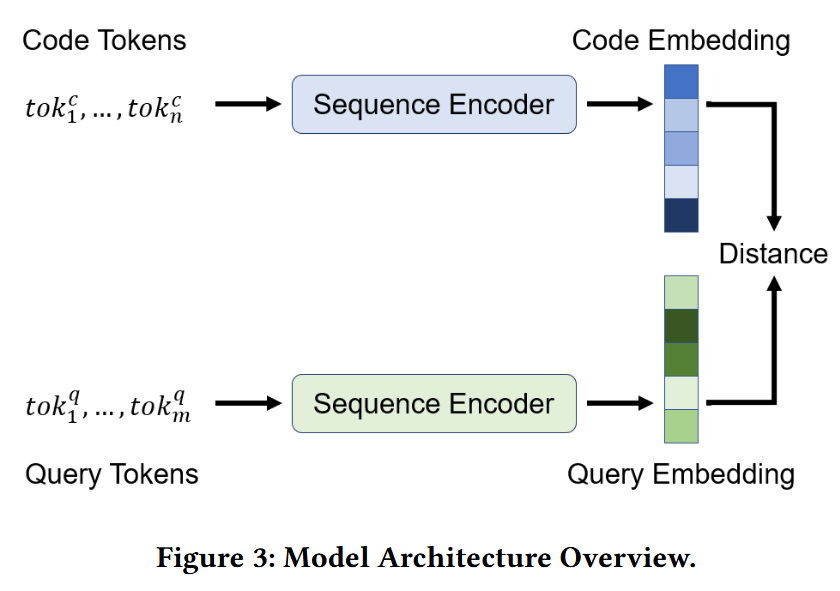
embedding生成
这里由于论文比较老,这里分词的方法还挺让我耳目一新的,论文主要涉及到了两个部分的分词,一个部分是代码部分的分词,另一部分是自然语言部分的分词(这里主要是英文的分词):
首先介绍代码部分的分词处理,由于代码中的function中常常出现类似于camelCase的变量名,如果直接视为一个token可能词表中没有对应的单词,这里的处理是将他们划分为subtoken,camel和case。接下来对应自然语言发处理则是基于byte-pair encoding)(BPE) ,BPE的优点是能处理罕见词例如:
“uninitializable” → ["un", "initial", "iza", "ble"]同时可以控制模型的词表大小(如 50k)提升泛化能力。
在生成词嵌入中,作者使用了4种模型:
Neural Bag of Words 、 Bidirectional RNN models 、1D Convolutional Neural Network 、Self-Attention
实验结果
本篇论文主要有两个实验:
一个是基于本文的语料库进行Mean Reciprocal Rank (MRR),这里将文档评论作为查询,然后再判断对应正确结果在999个干扰代码片段的代码rank是否靠前。
MRR 衡量“正确答案在搜索结果中的排名”——越靠前越好。
- 如果正确代码排在第 1 → 分数是 1
- 排在第 2 → 分数是 1/2
- 排在第 5 → 分数是 1/5
多个 query 取平均。
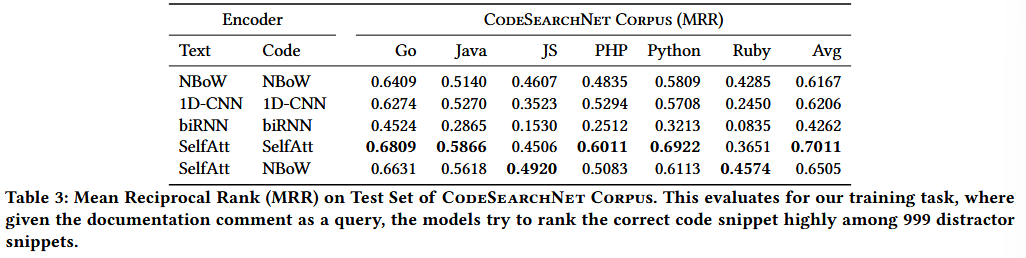
实验结果显示selfatt模型获得了最好的效果,评价检索正确结果的检索排名都是基本在前2。其他的差别不是太大,但是RNN显然能力最弱。
另一个的实验是基于对应的挑战赛上进行normalized discounted cumulative gain (NDCG):
NDCG 衡量的是 整个排序的质量,不是只看第一个正确项。
- 排名越靠前,得分越高
- 可以处理“多条结果都有不同相关性等级”的情况(relevance = 2, 1, 0)
非常适合代码检索这种“多个片段都可能部分正确”的任务。
其中
$$
\begin{aligned}
DCG = \sum_{i=1}^{n} \frac{2^{rel_i}-1}{\log_2(i+1)}
\end{aligned}
$$$$
\begin{aligned}
NDCG = \frac{DCG}{IDCG}
\end{aligned}
$$
rel_i是该 rank 是否 relevant(例如 2=非常相关, 1=相关,0=不相关),IDCG代表理想情况下排序rank正确的DCG例如任务:query “sort list descending”
系统返回 5 个代码片段:
Rank SnippetID Relevance rel 说明 1 s8 0 完全不相关 2 s14 2 完全正确 3 s33 1 部分正确 4 s21 0 无关 5 s42 1 较弱相关
Step 1: 计算 DCG
$$
\begin{aligned}
DCG &=
\frac{2^{0}-1}{\log_2(1+1)} +
\frac{2^{2}-1}{\log_2(2+1)} +
\frac{2^{1}-1}{\log_2(3+1)} +
\frac{2^{0}-1}{\log_2(4+1)} +
\frac{2^{1}-1}{\log_2(5+1)}
\end{aligned}
$$$$
\begin{aligned}
&=
0 +
\frac{3}{\log_2 3} +
\frac{1}{\log_2 4} +
0 +
\frac{1}{\log_2 6}
\end{aligned}
$$代入数值:
- Rank1: (1 – 1) / log₂ 2 = 0
- Rank2: (4 – 1) / log₂ 3 = 3 / 1.585 = 1.89
- Rank3: (2 – 1) / log₂ 4 = 1 / 2 = 0.5
- Rank4: 0
- Rank5: (2 – 1) / log₂ 6 = 1 / 2.585 = approx 0.387
DCG≈2.777
Step 2: 计算 iDCG(完美情况的 DCG)
完美排序应该把 rel=2 放前面,rel=1 的其次。
相关性降序排列:
理想 Rank Relevance 1 2 2 1 3 1 4 0 5 0 算 DCG:
- Rank1: (4−1)/log₂2 = 3
- Rank2: (2−1)/log₂3 = 0.63
- Rank3: (2−1)/log₂4 = 0.5
iDCG≈4.13
Step 3: 计算 NDCG
NDCG=DCG/iDCG=2.777/4.13≈0.67
越接近 1 越好,表示排序越准。
这里实验分别在对应挑战赛的人工标注的4000个数据上进行(within),这4k个数据中每组自然查询语言-代码片段对,都被人工标注上了相关度对。实验同时还在2百万个语料库中进行,虽然这里没人人工标注,这里我们可以默认为相关为1,不相关为0。
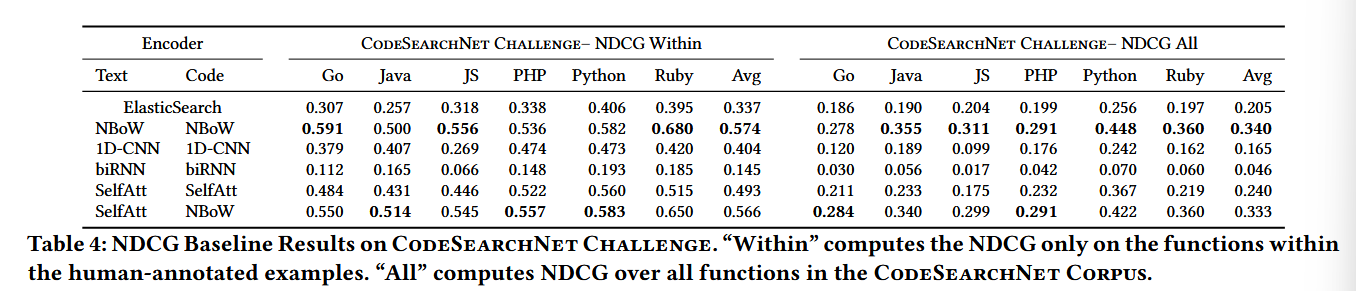
该部分显示NBOW的效果明显高于其他模型,由于神经词袋模型不在乎字符顺序,只在乎字符出现频率,可能该挑战赛中对应部分的数据还不够充分,或者现实代码检索任务中,检索结果的高低和关键词出现频率呈现强正相关,这都是NBOW模型杰出的可能原因。
潜在探索点
在结果中我们还发现了一个有趣的实验现象,不同的程序语言在不同的任务上最优情况并不一致,这可能是由于不同代码中自带的超图结构对应的空间曲率不同,未来可以从黎曼几何的非欧空间角度探究不同代码图的空间曲率对于相关任务的影响。