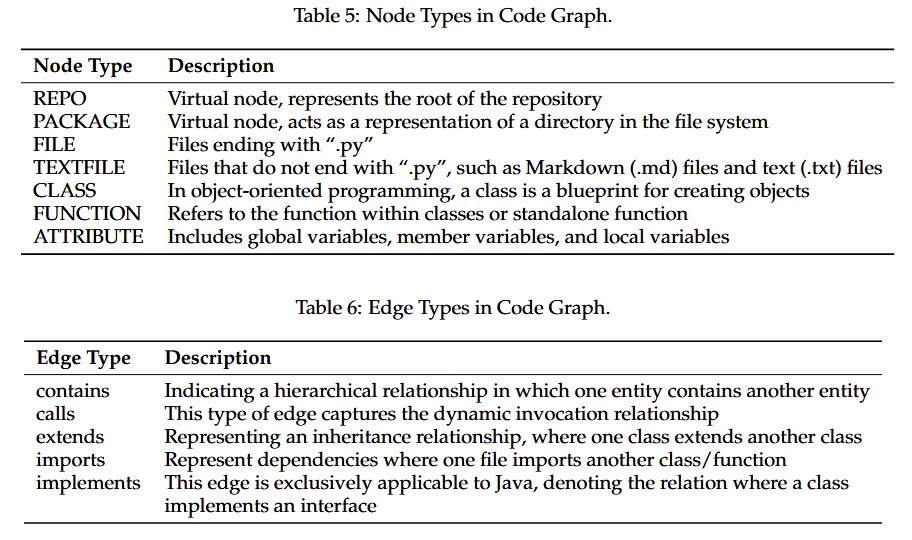
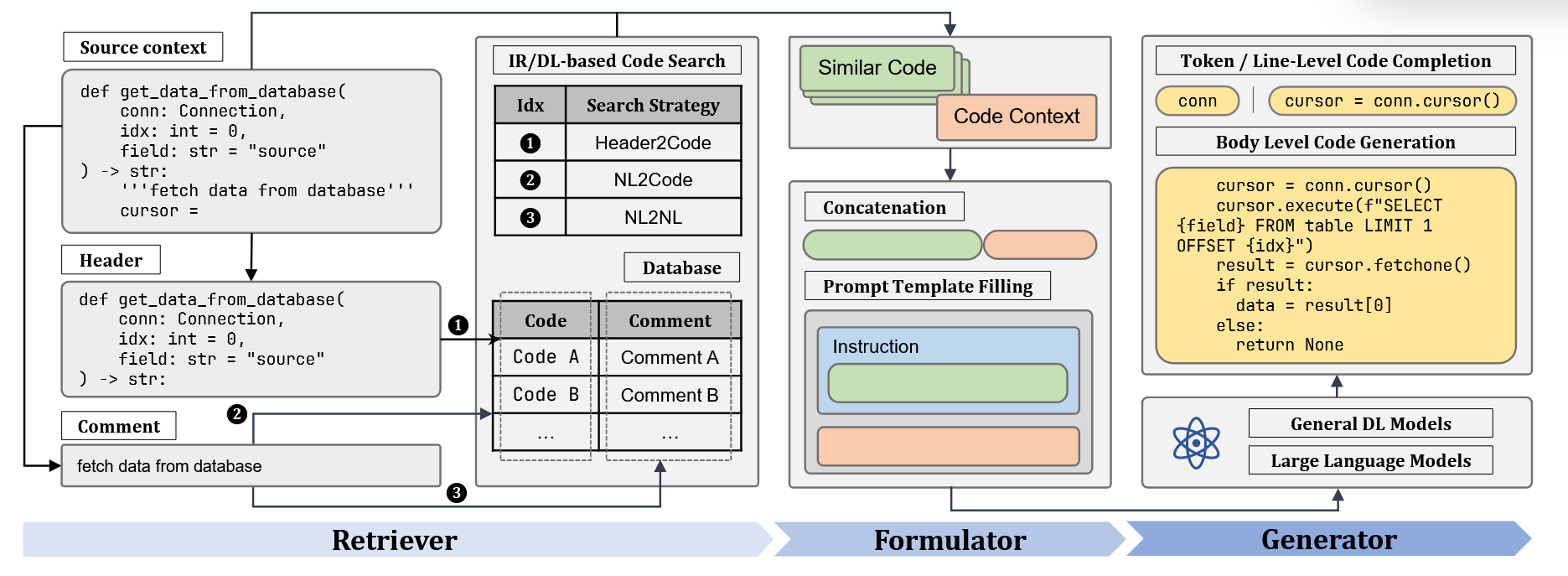
Task3 向量嵌入与初步检索
task3资料参考:all-in-rag/docs/chapter3 at main · datawhalechina/all-in-rag
这一章主要介绍将文本映射到固定低维、稠密向量空间的向量嵌入(embedding)过程,同时利用将分块后的知识库按每块映射到对应的向量数据库,接着我们在检索过程中,将我们的query也映射转为向量空间,最后按照向量之间的相似度将原知识库向量库排序,我们选取top-k的过程即可检索的过程。
1.向量嵌入
1.1 什么是Embedding?
向量嵌入(Embedding)是一种将真实世界中复杂、高维的数据对象(如文本、图像、音频、视频等)转换为数学上易于处理的、低维、稠密的连续数值向量的技术。
想象一下,我们将每一个词、每一段话、每一张图片都放在一个巨大的多维空间里,并给它一个独一无二的坐标。这个坐标就是一个向量,它“嵌入”了原始数据的所有关键信息。这个过程,就是 Embedding。
- 数据对象:任何信息,如文本“你好世界”,或一张猫的图片。
- Embedding 模型:一个深度学习模型,负责接收数据对象并进行转换。
- 输出向量:一个固定长度的一维数组,例如
[0.16, 0.29, -0.88, ...]。这个向量的维度(长度)通常在几百到几千之间。
1.2 Embedding的作用
Embedding 的真正威力在于,它产生的向量不是随机数值的堆砌,而是对数据语义的数学编码。
-
核心原则:在 Embedding 构建的向量空间中,语义上相似的对象,其对应的向量在空间中的距离会更近;而语义上不相关的对象,它们的向量距离会更远。
-
关键度量
:我们通常使用以下数学方法来衡量向量间的“距离”或“相似度”:
- 余弦相似度 (Cosine Similarity):计算两个向量夹角的余弦值。值越接近 1,代表方向越一致,语义越相似。这是最常用的度量方式。
- 点积 (Dot Product):计算两个向量的乘积和。在向量归一化后,点积等价于余弦相似度。
- 欧氏距离 (Euclidean Distance):计算两个向量在空间中的直线距离。距离越小,语义越相似。
1.3 RAG中的Embedding应用
在RAG中,可以说Embedding的效果决定了RAG检索的效果
RAG 的“检索”环节通常以基于 Embedding 的语义搜索为核心。通用流程如下:
- 离线索引构建:将知识库内文档切分后,使用 Embedding 模型将每个文档块(Chunk)转换为向量,存入专门的向量数据库中。
- 在线查询检索:当用户提出问题时,使用同一个 Embedding 模型将用户的问题也转换为一个向量。
- 相似度计算:在向量数据库中,计算“问题向量”与所有“文档块向量”的相似度。
- 召回上下文:选取相似度最高的 Top-K 个文档块,作为补充的上下文信息,与原始问题一同送给大语言模型(LLM)生成最终答案。
1.4 Embedding的技术发展
Embedding技术发展和自然语言处理紧密相关,
1.4.1 静态词嵌入
最早出现的相关应用模型为例如Word2Vec(2013),这个模型是一个静态词嵌入模型,是上下文无关的表示。为什么说是静态和上下文无关呢?主要是因为该模型为词汇表中的每个单词生成一个固定的、与上下文无关的向量,它处理不了一词多义的情况。
不过它也有跨时代的创新,它支持词汇映射的向量之后和语义相近程度呈正相关。固定语义越近,其映射后的词汇向量也越近。
1.4.2 动态上下文嵌入
2017年,Transformer 架构的诞生带来了自注意力机制(Self-Attention),它允许模型在生成一个词的向量时,动态地考虑句子中所有其他词的影响。基于此,2018年 BERT 模型利用 Transformer 的编码器,通过掩码语言模型(MLM)等自监督任务进行预训练,生成了深度上下文相关的嵌入。同一个词在不同语境中会生成不同的向量,这有效解决了静态嵌入的一词多义难题。
1.4.3 嵌入模型bert
下面介绍当前主流的嵌入模型bert(其他嵌入模型多为其变体),现代嵌入模型的核心通常是 Transformer 的编码器(Encoder)部分,BERT 就是其中的典型代表。它通过堆叠多个 Transformer Encoder 层来构建一个深度的双向表示学习网络。
1.4.3.1 训练方式
bert的成功某种程度上是归功于其自监督学习策略,它允许模型从海量的、无标注的文本数据中学习知识。
例如
随机掩码语言模型(Masked Language Model, MLM):随机将句子中15%的token替换为【mask】标志,然后让模型去预测这些被遮盖住的原始token是什么,促进模型学习每个词元和其上下文之间的关系。
下一句预测(Next Sentence Prediction, NSP):构造每个样本包含两个句子A和B,其中 50% 的样本,B 是 A 的真实下一句(IsNext);另外 50% 的样本,B 是从语料库中随机抽取的句子(NotNext)。接着让模型判断B是否是A的下一句。
虽然 MLM 和 NSP 赋予了模型强大的基础语义理解能力,但为了在检索任务中表现更佳,现代嵌入模型通常会引入更具针对性的训练策略。
- 度量学习 (Metric Learning):
- 思想:直接以“相似度”作为优化目标。
- 方法:收集大量相关的文本对(例如,(问题,答案)、(新闻标题,正文))。训练的目标是优化向量空间中的相对距离:让“正例对”的向量表示在空间中被“拉近”,而“负例对”的向量表示被“推远”。关键在于优化排序关系,而非追求绝对的相似度值(如 1 或 0),因为过度追求极端值可能导致模型过拟合。
- 对比学习 (Contrastive Learning):
- 思想:在向量空间中,将相似的样本“拉近”,将不相似的样本“推远”。
- 方法:构建一个三元组(Anchor, Positive, Negative)。其中,Anchor 和 Positive 是相关的(例如,同一个问题的两种不同问法),Anchor 和 Negative 是不相关的。训练的目标是让
distance(Anchor, Positive)尽可能小,同时让distance(Anchor, Negative)尽可能大。
1.4.3.2 bert模型选取
MTEB (Massive Text Embedding Benchmark) 是一个由 Hugging Face 维护的、全面的文本嵌入模型评测基准。它涵盖了分类、聚类、检索、排序等多种任务,并提供了公开的排行榜,为评估和选择嵌入模型提供了重要的参考依据。
1.5 多模态嵌入
之前的内容主要是实现了将文本内容的嵌入过程,然而现实需求中,除了文本要求,往往还有音频、图片、视频等等的多媒体,如果说我们有进行文本查询,知识库中存在多媒体文件,同时需要检索对比到他们,所以我们就需要具备将这些多媒体文件也嵌入(和文本一样映射到相同向量空间)的能力。
实现这一目标的关键,在于解决 跨模态对齐 (Cross-modal Alignment) 的挑战。以对比学习、视觉 Transformer (ViT) 等技术为代表的突破,让模型能够学习到不同模态数据之间的语义关联,最终催生了像 CLIP 这样的模型。
CLIP 的架构清晰简洁。它采用双编码器架构 (Dual-Encoder Architecture),包含一个图像编码器和一个文本编码器,分别将图像和文本映射到同一个共享的向量空间中。
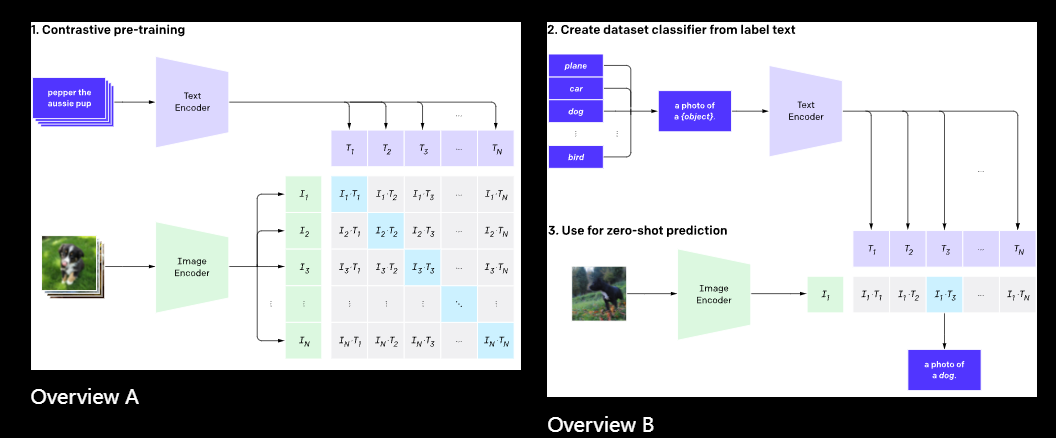
为了让两个编码器学会“对齐”不同模态的语义,CLIP在训练中采用了对比学习 (Contrastive Learning),这种大规模的对比学习赋予了CLIP有效的零样本识别能力,具有良好的泛化能力。
1.5.1 bge-visualized-m3模型
虽然 CLIP 为图文预训练提供了重要基础,但多模态领域的研究迅速发展,涌现了许多针对不同目标和场景进行优化的模型。例如,BLIP 系列专注于提升细粒度的图文理解与生成能力,而 ALIGN 则证明了利用海量噪声数据进行大规模训练的有效性。
在众多优秀的模型中,由北京智源人工智能研究院(BAAI)开发的 BGE-M3 是一个很有代表性的现代多模态嵌入模型。它在多语言、多功能和多粒度处理上都表现出色,体现了当前技术向“更统一、更全面”发展的趋势。
BGE-M3 的核心特性可以概括为“M3”:
- 多语言性 (Multi-Linguality):原生支持超过 100 种语言的文本与图像处理,能够轻松实现跨语言的图文检索。
- 多功能性 (Multi-Functionality):在单一模型内同时支持密集检索(Dense Retrieval)、多向量检索(Multi-Vector Retrieval)和稀疏检索(Sparse Retrieval),为不同应用场景提供了灵活的检索策略。
- 多粒度性 (Multi-Granularity):能够有效处理从短句到长达 8192 个 token 的长文档,覆盖了更广泛的应用需求。
1.5.1.1 代码样例
接下来我们来介绍bge-visualized-m3模型的使用和实际效果,
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import torch
from visual_bge.visual_bge.visual_bge.modeling import Visualized_BGE
model = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5",
model_weight="../../models/bge/Visualized_base_en_v1.5.pth")
model.eval()
with torch.no_grad():
text_emb = model.encode(text="datawhale开源组织的logo")
img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png")
multi_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png", text="datawhale开源组织的logo")
img_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png")
multi_emb_2 = model.encode(image="../../data/C3/imgs/datawhale02.png", text="datawhale开源组织的logo")
# 计算相似度
sim_1 = img_emb_1 @ img_emb_2.T
sim_2 = img_emb_1 @ multi_emb_1.T
sim_3 = text_emb @ multi_emb_1.T
sim_4 = multi_emb_1 @ multi_emb_2.T
print("=== 相似度计算结果 ===")
print(f"纯图像 vs 纯图像: {sim_1}")
print(f"图文结合1 vs 纯图像: {sim_2}")
print(f"图文结合1 vs 纯文本: {sim_3}")
print(f"图文结合1 vs 图文结合2: {sim_4}")代码运行结果:
=== 相似度计算结果 ===
纯图像 vs 纯图像: tensor([[0.8318]])
图文结合1 vs 纯图像: tensor([[0.8291]])
图文结合1 vs 纯文本: tensor([[0.7627]])
图文结合1 vs 图文结合2: tensor([[0.9058]])如果将尝试把代码中的部分文本替换一下,比如将datawhale开源组织的logo替换为蓝鲸
代码运行结果1:
=== 相似度计算结果 ===
纯图像 vs 纯图像: tensor([[0.8318]])
图文结合1 vs 纯图像: tensor([[0.9926]])
图文结合1 vs 纯文本: tensor([[0.4470]])
图文结合1 vs 图文结合2: tensor([[0.8323]])上面的代码主要使用了三种编码类型,文本编码、图像编码、文本和图像混合编码
通过测试我发现该模型支持文本检索文本,文本检索图文混合,图片检索图片,图片检索图文混合,但是在图片检索文字,和文字检索图片的时候效果比较差,几乎没有明显效果
例如我将文本“文本”、“人类”、“小狗”,“蓝鲸”编码之后,对比文本蓝鲸他们编码后的向量的相似度:
text_emb = model.encode(text="蓝鲸")
text_emb1 = model.encode(text="小狗")
text_emb2 = model.encode(text="人类")
text_emb3 = model.encode(text="鱼")
print("=== 相似度计算结果 ===")
print(text_emb @ text_emb1.T)
print(text_emb @ text_emb2.T)
print(text_emb @ text_emb3.T)代码结果:
=== 相似度计算结果 ===
tensor([[0.7065]]) # 蓝鲸和小狗
tensor([[0.7817]]) # 蓝鲸和人类
tensor([[0.9222]]) # 蓝鲸和鱼但是如果我们将文本蓝鲸
换成logo版Q版图片蓝鲸之后,再和所有文本对比:
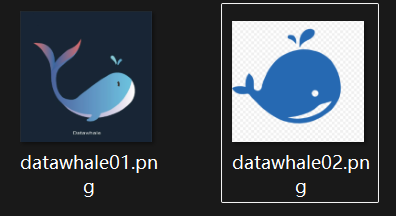
text_emb = model.encode(text="蓝鲸")
text_emb1 = model.encode(text="小狗")
text_emb2 = model.encode(text="人类")
text_emb3 = model.encode(text="鱼")
img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png")
print(img_emb_1 @ text_emb.T)
print(img_emb_1 @ text_emb1.T)
print(img_emb_1 @ text_emb2.T)
print(img_emb_1 @ text_emb3.T)代码结果:
tensor([[0.4103]]) # 图片蓝鲸logo 和 蓝鲸
tensor([[0.4848]]) # 图片蓝鲸logo 和 小狗
tensor([[0.4057]]) # 图片蓝鲸logo 和 人类
tensor([[0.4596]]) # 图片蓝鲸logo 和 鱼由上结果我们发现如果直接跨模态检索效果将会差很多。
所以这里我去huggingface重新找了一个模型:
jinaai/jina-clip-v2
1.5.2 jinaai/jina-clip-v2模型
模型描述
- 名称:Jina CLIP v2 — “Multilingual Multimodal Embeddings for Text & Images” Hugging Face
- 用途:用于将文本和图像映射到同一个嵌入空间,以做跨模态检索、图文检索、以及(text-text)检索等任务。 Hugging Face
- 特点:
- 多语言支持 — 支持约 89 种语言。 Hugging Face
- 更高图片分辨率 — 图片输入最大为 512×512,这相比某些早期 CLIP 型模型(例如用 224×224)能够捕捉更细节的视觉特征。 Hugging Face
- 灵活嵌入维度(Matryoshka Representation) — 可以 “裁剪”输出的嵌入维度,比如你可以用完整 1024 维,也可以截断到较低维度(比如 64、512 等),节省存储/计算。 Hugging Face
- 强大的视觉编码器 + 文本编码器组合 — 视觉用的是 EVA02-L14,文本用的是 Jina-XLM-RoBERTa。 Hugging Face
from transformers import AutoProcessor, AutoModel
model = AutoModel.from_pretrained('jinaai/jina-clip-v2', trust_remote_code=True)
processor = AutoProcessor.from_pretrained('jinaai/jina-clip-v2', trust_remote_code=True,use_fast=True)
# 文本编码
text_embeddings = model.encode_text(
["蓝鲸"],
truncate_dim=512
)
text_embeddings1 = model.encode_text(
["人类"],
truncate_dim=512
)
text_embeddings2 = model.encode_text(
["小狗"],
truncate_dim=512
)
text_embeddings3 = model.encode_text(
["鱼"],
truncate_dim=512
)
# 图片编码
image_embeddings = model.encode_image(
["../../data/C3/imgs/datawhale01.png"],
truncate_dim=512
)
image_embeddings1 = model.encode_image(
["../../data/C3/imgs/datawhale02.png"],
truncate_dim=512
)
# 文本检索图片:计算相似度
print(text_embeddings @ image_embeddings.T)
print(text_embeddings1 @ image_embeddings.T)
print(text_embeddings2 @ image_embeddings.T)
print(text_embeddings3 @ image_embeddings.T)
print(image_embeddings @ image_embeddings1.T)结果展示:
[[0.29817224]] # 蓝鲸文本 和 蓝鲸图片logo
[[0.14926076]] # 人类文本 和 蓝鲸图片logo
[[0.14426407]] # 小狗文本 和 蓝鲸图片logo
[[0.241086]] # 鱼文本 和 蓝鲸图片logo
[[0.8685434]]# 蓝鲸图片logo1 和蓝鲸图片logo由上面的测试明显发现jinaai/jina-clip-v2模型在将文本和图片编码后,不同类别的嵌入映射后的向量明显区别程度优于前一个模型。
2.初步检索
在完成对应文本的分块、嵌入之后,我们的知识库已经变成了按块为单位的固定维度的向量集合,接下来我们需要面临的问题则是如何快速、准确地从海量向量中找到与用户查询最相似的那几个?
2.1 向量数据库
所以这里我们将会引入一个能高效处理海量高位向量的向量数据库,其主要功能可以概况为:
- 高效的相似性搜索:这是向量数据库最重要的功能。它利用专门的索引技术(如 HNSW, IVF),能够在数十亿级别的向量中实现毫秒级的近似最近邻(ANN)查询,快速找到与给定查询最相似的数据。
- 高维数据存储与管理:专门为存储高维向量(通常维度成百上千)而优化,支持对向量数据进行增、删、改、查等基本操作。
- 丰富的查询能力:除了基本的相似性搜索,还支持按标量字段过滤查询(例如,在搜索相似图片的同时,指定
年份 > 2023)、范围查询和聚类分析等,满足复杂业务需求。 - 可扩展与高可用:现代向量数据库通常采用分布式架构,具备良好的水平扩展能力和容错性,能够通过增加节点来应对数据量的增长,并确保服务的稳定可靠。
- 数据与模型生态集成:与主流的 AI 框架(如 LangChain, LlamaIndex)和机器学习工作流无缝集成,简化了从模型训练到向量检索的应用开发流程。
2.1.1 工作原理
向量数据库的核心是高效处理高维向量的相似性搜索。向量是一组有序的数值,可以表示文本、图像、音频等复杂数据的特征或属性。在 RAG 系统中,向量一般通过嵌入模型将原始数据转换为高维向量表示,比如上一节的图文示例。
向量数据库通常采用四层架构,通过以下技术手段实现高效相似性搜索:
- 存储层:存储向量数据和元数据,优化存储效率,支持分布式存储
- 索引层:维护索引算法(HNSW、LSH、PQ等),创建和优化索引,支持索引调整
- 查询层:处理查询请求,支持混合查询,实现查询优化
- 服务层:管理客户端连接,提供监控和日志,实现安全管理
主要技术手段包括:
- 基于树的方法:如 Annoy 使用的随机投影树,通过树形结构实现对数复杂度的搜索
- 基于哈希的方法:如 LSH(局部敏感哈希),通过哈希函数将相似向量映射到同一“桶”
- 基于图的方法:如 HNSW(分层可导航小世界图),通过多层邻近图结构实现快速搜索
- 基于量化的方法:如 Faiss 的 IVF 和 PQ,通过聚类和量化压缩向量
2.1.2 HNSW & IVF
这里我们分别测试了HNSW (Hierarchical Navigable Small World Graph)分层可导航小世界图和IVF (Inverted File Index)倒排文件索引
2.1.2.1 HNSW
- 本质上是把向量组织成一个 分层的图结构。
- 每一层的节点只连少量的边,但保证从一个节点可以“跳”到另一个区域。
- 查询时,从顶层开始,逐步往下层走,每层都快速缩小搜索范围,直到找到和查询向量最接近的点。
例子
假设有 1 亿张图片的向量,我们想找“最像猫的图片”:
- 从顶层随机挑一个点作为入口,计算与查询向量的距离;
- 沿着边不断移动,直到不能再找到更近的;
- 逐层下降,搜索范围越来越小;
- 最后在底层找到最相似的前 10 张猫图。
👉 全程只需要访问几千个点,而不是 1 亿个。
2.1.2.2 IVF
- 先用聚类(比如 K-Means)把所有向量分成很多个簇(cluster),相当于建立“分桶”。
- 查询时,先找到查询向量最接近的几个簇,然后只在这些簇里搜索,而不是全量搜索。
例子
假设有 10 亿条文本向量:
- 先把它们分成 100 万个簇;
- 某个查询句子“我想买手机”对应的向量可能落在簇 #12345;
- 只在簇 #12345 附近的向量里搜索,而不是 10 亿条全量扫描;
- 这样查询时间就能缩短到毫秒级。
测试代码
import numpy as np
import faiss
# ------------------------
# 1. 生成模拟数据
# ------------------------
d = 128 # 向量维度
nb = 100000 # 数据库中的向量数量(10万条模拟数据)
nq = 5 # 查询向量数量
np.random.seed(123)
# 数据库向量(归一化方便做相似度)
xb = np.random.random((nb, d)).astype('float32') # 随机生成一个nb个d维的float类型的向量
xb = xb / np.linalg.norm(xb, axis=1, keepdims=True) # 将这些向量归一化处理
# 查询向量
xq = np.random.random((nq, d)).astype('float32') # 生成5条d维度的float类型的向量
xq = xq / np.linalg.norm(xq, axis=1, keepdims=True) # 将查询向量归一化处理
# ------------------------
# 2. 建立 IVF 索引
# ------------------------
nlist = 100 # 聚类桶数量
nprobe = 10 # 查询时搜索的桶数
quantizer = faiss.IndexFlatL2(d) # 底层量化器
index_ivf = faiss.IndexIVFFlat(quantizer, d, nlist)
# 训练聚类中心(IVF 必须先训练)
index_ivf.train(xb)
# 添加向量到索引
index_ivf.add(xb)
# 设置搜索范围
index_ivf.nprobe = nprobe
print("IVF 索引搜索:")
D, I = index_ivf.search(xq, k=5) # 搜索 top-5
print(I) # 返回的最近邻向量下标
# ------------------------
# 3. 建立 HNSW 索引
# ------------------------
M = 32 # 每个点的出边数量
index_hnsw = faiss.IndexHNSWFlat(d, M)
# 添加向量
index_hnsw.add(xb)
print("\nHNSW 索引搜索:")
D, I = index_hnsw.search(xq, k=5)
print(I)
运行结果:
IVF 索引搜索:
[[56015 82895 18780 43696 1975]
[25189 22635 43569 34514 35586]
[21650 45327 35265 45781 38029]
[58070 92783 98773 34923 31592]
[42264 57267 99887 54563 74868]]
HNSW 索引搜索:
[[51673 90140 39334 21241 61810]
[36184 70444 36993 74736 80996]
[45327 96297 37659 29117 59793]
[56663 96691 54919 62865 50519]
[31341 66499 42264 18154 57267]]上面每行都代表每次查询向量在数据库中查询的结果相似度的前5个符合的数据库中数据的下标。只看top-5的结果我们发现两种方式还是有明显区别的。
2.1.3 本地向量存储:FAISS
当前主流的向量数据库产品有很多,包括但不限于Pinecone、Milvus、Qdrant 、Weaviate 、Chroma等等
选择建议:
- 新手入门/小型项目:从
ChromaDB或FAISS开始是最佳选择。它们与 LangChain/LlamaIndex 紧密集成,几行代码就能运行,且能满足基本的存储和检索需求。 - 生产环境/大规模应用:当数据量超过百万级,或需要高并发、实时更新、复杂元数据过滤时,应考虑更专业的解决方案,如
Milvus、Weaviate或云服务Pinecone。
下面我们即以FAISS为例
FAISS (Facebook AI Similarity Search) 是一个由 Facebook AI Research 开发的高性能库,专门用于高效的相似性搜索和密集向量聚类。当与 LangChain 结合使用时,它可以作为一个强大的本地向量存储方案,非常适合快速原型设计和中小型应用。
与 ChromaDB 等数据库不同,FAISS 本质上是一个算法库,它将索引直接保存为本地文件(一个 .faiss 索引文件和一个 .pkl 映射文件),而非运行一个数据库服务。这种方式轻量且高效。
代码部分:
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_core.documents import Document
# 1. 示例文本和嵌入模型
texts = [
"张三是法外狂徒",
"FAISS是一个用于高效相似性搜索和密集向量聚类的库。",
"LangChain是一个用于开发由语言模型驱动的应用程序的框架。"
]
docs = [Document(page_content=t) for t in texts]
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 2. 创建向量存储并保存到本地
vectorstore = FAISS.from_documents(docs, embeddings)
local_faiss_path = "./faiss_index_store"
vectorstore.save_local(local_faiss_path)
print(f"FAISS index has been saved to {local_faiss_path}")
# 3. 加载索引并执行查询
# 加载时需指定相同的嵌入模型,并允许反序列化
loaded_vectorstore = FAISS.load_local(
local_faiss_path,
embeddings,
allow_dangerous_deserialization=True
)
# 相似性搜索
query = "FAISS是做什么的?"
results = loaded_vectorstore.similarity_search(query, k=1)
print(f"\n查询: '{query}'")
print("相似度最高的文档:")
for doc in results:
print(f"- {doc.page_content}")上面的代码就是一个简洁的 创建知识库——分页后嵌入后存储——加载索引——检索的过程
结果输出:
FAISS index has been saved to ./faiss_index_store
查询: 'FAISS是做什么的?'
相似度最高的文档:
- FAISS是一个用于高效相似性搜索和密集向量聚类的库。索引创建实现细节: 通过深入 LangChain 源码,可以发现索引创建是一个分层、解耦的过程,主要涉及以下几个方法的嵌套调用:
from_documents(封装层):- 这是我们直接调用的方法。它的职责很简单:从输入的
Document对象列表中提取出纯文本内容 (page_content) 和元数据 (metadata)。 - 然后,它将这些提取出的信息传递给核心的
from_texts方法。
- 这是我们直接调用的方法。它的职责很简单:从输入的
from_texts(向量化入口):- 这个方法是面向用户的核心入口。它接收文本列表,并执行关键的第一步:调用
embedding.embed_documents(texts),将所有文本批量转换为向量。 - 完成向量化后,它并不直接处理索引构建,而是将生成的向量和其他所有信息(文本、元数据等)传递给一个内部的辅助方法
__from。
- 这个方法是面向用户的核心入口。它接收文本列表,并执行关键的第一步:调用
__from(构建索引框架):- 这是一个内部方法,负责搭建 FAISS 向量存储的“空框架”。
- 它会根据指定的距离策略(默认为 L2 欧氏距离)初始化一个空的 FAISS 索引结构(如
faiss.IndexFlatL2)。 - 同时,它也准备好了用于存储文档原文的
docstore和用于连接 FAISS 索引与文档的index_to_docstore_id映射。 - 最后,它调用另一个内部方法
__add来完成数据的填充。
__add(填充数据):- 这是真正执行数据添加操作的核心。它接收到向量、文本和元数据后,执行以下关键操作:
- 添加向量: 将向量列表转换为 FAISS 需要的
numpy数组,并调用self.index.add(vector)将其批量添加到 FAISS 索引中。 - 存储文档: 将文本和元数据打包成
Document对象,存入docstore。 - 建立映射: 更新
index_to_docstore_id字典,建立起 FAISS 内部的整数 ID(如 0, 1, 2…)到我们文档唯一 ID 的映射关系。
- 添加向量: 将向量列表转换为 FAISS 需要的
- 这是真正执行数据添加操作的核心。它接收到向量、文本和元数据后,执行以下关键操作:
2.2 Milvus介绍及多模态检索实践
2.2.1 简介
Milvus 是一个开源的、专为大规模向量相似性搜索和分析而设计的向量数据库。它诞生于 Zilliz 公司,并已成为 LF AI & Data 基金会的顶级项目,在AI领域拥有广泛的应用。
与 FAISS、ChromaDB 等轻量级本地存储方案不同,Milvus 从设计之初就瞄准了生产环境。其采用云原生架构,具备高可用、高性能、易扩展的特性,能够处理十亿、百亿甚至更大规模的向量数据。
官网地址: https://milvus.io/
GitHub: https://github.com/milvus-io/milvus
2.2.2 核心组件
Milvus的组件结构主要可以概括collection和index以及检索部分:
下面我们逐个介绍:
2.2.2.1 Collection
Collection 好比为 Milvus 的骨架,其具体内容如下所示
- Collection (集合): 相当于一个图书馆,是所有数据的顶层容器。一个 Collection 可以包含多个 Partition,每个 Partition 可以包含多个 Entity。
- Partition (分区): 相当于图书馆里的不同区域(如“小说区”、“科技区”),将数据物理隔离,让检索更高效。
- Schema (模式): 相当于图书馆的图书卡片规则,定义了每本书(数据)必须登记哪些信息(字段)。
- Entity (实体): 相当于一本具体的书,是数据本身。
- Alias (别名): 相当于一个动态的推荐书单(如“本周精选”),它可以指向某个具体的 Collection,方便应用层调用,实现数据更新时的无缝切换。
每个区详细的内容介绍详见:all-in-rag/docs/chapter3/09_milvus.md
2.2.2.2 index
如果说 Collection 是 Milvus 的骨架,那么索引 (Index) 就是其加速检索的神经系统。从宏观上看,索引本身就是一种为了加速查询而设计的复杂数据结构。对向量数据创建索引后,Milvus 可以极大地提升向量相似性搜索的速度,代价是会占用额外的存储和内存资源。
其索引的内部组件为:
- 数据结构:这是索引的骨架,定义了向量的组织方式(如 HNSW 中的图结构)。
- 量化(可选):数据压缩技术,通过降低向量精度来减少内存占用和加速计算。
- 结果精炼(可选):在找到初步候选集后,进行更精确的计算以优化最终结果。
Milvus 支持对标量字段和向量字段分别创建索引。
- 标量字段索引:主要用于加速元数据过滤,常用的有
INVERTED、BITMAP等。通常使用推荐的索引类型即可。 - 向量字段索引:这是 Milvus 的核心。选择合适的向量索引是在查询性能、召回率和内存占用之间做出权衡的艺术。
同时Milvus 提供了多种向量索引算法,以适应不同的应用场景。以下是几种最核心的类型:
- FLAT (精确查找)
- 原理:暴力搜索(Brute-force Search)。它会计算查询向量与集合中所有向量之间的实际距离,返回最精确的结果。
- 优点:100% 的召回率,结果最准确。
- 缺点:速度慢,内存占用大,不适合海量数据。
- 适用场景:对精度要求极高,且数据规模较小(百万级以内)的场景。
- IVF 系列 (倒排文件索引)
- 原理:类似于书籍的目录。它首先通过聚类将所有向量分成多个“桶”(
nlist),查询时,先找到最相似的几个“桶”,然后只在这几个桶内进行精确搜索。IVF_FLAT、IVF_SQ8、IVF_PQ是其不同变体,主要区别在于是否对桶内向量进行了压缩(量化)。 - 优点:通过缩小搜索范围,极大地提升了检索速度,是性能和效果之间很好的平衡。
- 缺点:召回率不是100%,因为相关向量可能被分到了未被搜索的桶中。
- 适用场景:通用场景,尤其适合需要高吞吐量的大规模数据集。
- 原理:类似于书籍的目录。它首先通过聚类将所有向量分成多个“桶”(
- HNSW (基于图的索引)
- 原理:构建一个多层的邻近图。查询时从最上层的稀疏图开始,快速定位到目标区域,然后在下层的密集图中进行精确搜索。
- 优点:检索速度极快,召回率高,尤其擅长处理高维数据和低延迟查询。
- 缺点:内存占用非常大,构建索引的时间也较长。
- 适用场景:对查询延迟有严格要求(如实时推荐、在线搜索)的场景。
- DiskANN (基于磁盘的索引)
- 原理:一种为在 SSD 等高速磁盘上运行而优化的图索引。
- 优点:支持远超内存容量的海量数据集(十亿级甚至更多),同时保持较低的查询延迟。
- 缺点:相比纯内存索引,延迟稍高。
- 适用场景:数据规模巨大,无法全部加载到内存的场景。
2.2.2.3 检索
拥有了数据容器 (Collection) 和检索引擎 (Index) 后,最后一步就是从海量数据中高效地检索信息。
这里的检索包含基础向量检索 (ANN Search),其中ANN 代表近似最近邻 (Approximate Nearest Neighbor)。
除了这个以外,还有一些增强检索功能:
过滤检索 (Filtered Search): 工作原理:先根据提供的过滤表达式 (filter) 筛选出符合条件的实体,然后仅在这个子集内执行 ANN 检索。这极大地提高了查询的精准度。
范围检索 (Range Search):工作原理:范围检索允许定义一个距离(或相似度)的阈值范围。Milvus 会返回所有与查询向量的距离落在这个范围内的实体
多向量混合检索 (Hybrid Search): 工作原理:
- 并行检索:应用针对不同的向量字段(如一个用于文本语义的密集向量,一个用于关键词匹配的稀疏向量,一个用于图像内容的多模态向量)分别发起 ANN 检索请求。
- 结果融合 (Rerank):Milvus 使用一个重排策略(Reranker)将来自不同检索流的结果合并成一个统一的、更高质量的排序列表。常用的策略有
RRFRanker(平衡各方结果)和WeightedRanker(可为特定字段结果加权)。
分组检索 (Grouping Search): 工作原理:分组检索允许指定一个字段(如 document_id)对结果进行分组。Milvus 会在检索后,确保返回的结果中每个组(每个 document_id)只出现一次(或指定的次数),且返回的是该组内与查询最相似的那个实体。
2.2.3 milvus多模态实践部分
首先准备部分我们需要先将下载milvus 官方的docker-compose.yml 文件,并且输入docker compose up -d自动拉去所需的镜像并且启动三个容器。这部分操作过程详见笔记all-in-rag/docs/chapter3/09_milvus.md
顺利启动之后我们再在命令行输入docker ps,如下显示即为成功启动:
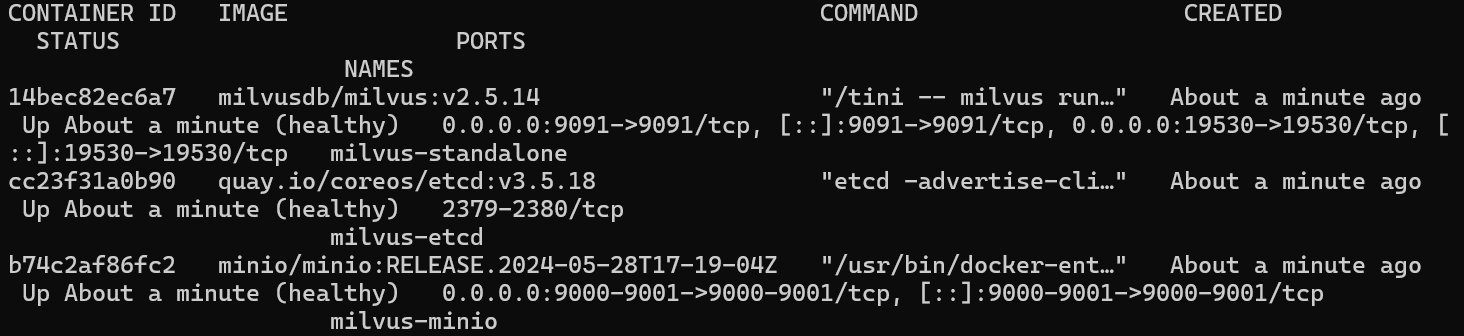
接下来先展示代码部分:
import os
from tqdm import tqdm
from glob import glob
import torch
from visual_bge.visual_bge.modeling import Visualized_BGE
from pymilvus import MilvusClient, FieldSchema, CollectionSchema, DataType
import numpy as np
import cv2
from PIL import Image
# 1. 初始化设置
MODEL_NAME = "BAAI/bge-base-en-v1.5"
MODEL_PATH = "../../models/bge/Visualized_base_en_v1.5.pth"
DATA_DIR = "../../data/C3"
COLLECTION_NAME = "multimodal_demo"
MILVUS_URI = "http://localhost:19530"
# 2. 定义工具 (编码器和可视化函数)
class Encoder:
"""编码器类,用于将图像和文本编码为向量。"""
def __init__(self, model_name: str, model_path: str):
# 加载模型和对应模型权重,并且开启评估模式
self.model = Visualized_BGE(model_name_bge=model_name, model_weight=model_path)
self.model.eval()
# 查询编码,默认查询包含图片和文本描述
def encode_query(self, image_path: str, text: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path, text=text)
return query_emb.tolist()[0]
# 仅仅编码图片
def encode_image(self, image_path: str) -> list[float]:
with torch.no_grad():
query_emb = self.model.encode(image=image_path)
return query_emb.tolist()[0]
# 结果可视化,将原图放在左下角,结果放在右上角,
def visualize_results(query_image_path: str, retrieved_images: list, img_height: int = 300, img_width: int = 300, row_count: int = 3) -> np.ndarray:
"""从检索到的图像列表创建一个全景图用于可视化。"""
panoramic_width = img_width * row_count
panoramic_height = img_height * row_count
# 创造一个正方形的空白区域,用于展示结果
panoramic_image = np.full((panoramic_height, panoramic_width, 3), 255, dtype=np.uint8)
# 创造一个空白区域用于存放原图
query_display_area = np.full((panoramic_height, img_width, 3), 255, dtype=np.uint8)
# 处理查询图像 将查询图片放在原图区域的最下方
query_pil = Image.open(query_image_path).convert("RGB")
query_cv = np.array(query_pil)[:, :, ::-1]
resized_query = cv2.resize(query_cv, (img_width, img_height))
bordered_query = cv2.copyMakeBorder(resized_query, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=(255, 0, 0))
query_display_area[img_height * (row_count - 1):, :] = cv2.resize(bordered_query, (img_width, img_height))
cv2.putText(query_display_area, "Query", (10, panoramic_height - 20), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
# 处理检索到的图像
for i, img_path in enumerate(retrieved_images):
row, col = i // row_count, i % row_count
start_row, start_col = row * img_height, col * img_width
retrieved_pil = Image.open(img_path).convert("RGB")
retrieved_cv = np.array(retrieved_pil)[:, :, ::-1]
resized_retrieved = cv2.resize(retrieved_cv, (img_width - 4, img_height - 4))
bordered_retrieved = cv2.copyMakeBorder(resized_retrieved, 2, 2, 2, 2, cv2.BORDER_CONSTANT, value=(0, 0, 0))
panoramic_image[start_row:start_row + img_height, start_col:start_col + img_width] = bordered_retrieved
# 添加索引号
cv2.putText(panoramic_image, str(i), (start_col + 10, start_row + 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
return np.hstack([query_display_area, panoramic_image])
# 3. 初始化客户端
print("--> 正在初始化编码器和Milvus客户端...")
# 初始化编码器模型
encoder = Encoder(MODEL_NAME, MODEL_PATH)
# 连接本地milvus服务端
milvus_client = MilvusClient(uri=MILVUS_URI)
# 4. 创建 Milvus Collection
print(f"\n--> 正在创建 Collection '{COLLECTION_NAME}'")
if milvus_client.has_collection(COLLECTION_NAME):
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除已存在的 Collection: '{COLLECTION_NAME}'")
image_list = glob(os.path.join(DATA_DIR, "dragon", "*.png"))
if not image_list:
raise FileNotFoundError(f"在 {DATA_DIR}/dragon/ 中未找到任何 .png 图像。")
# 求编码后向量维度数
dim = len(encoder.encode_image(image_list[0]))
# 创建数据库的schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim),
FieldSchema(name="image_path", dtype=DataType.VARCHAR, max_length=512),
]
# 创建集合 Schema
schema = CollectionSchema(fields, description="多模态图文检索")
print("Schema 结构:")
print(schema)
# 创建集合
milvus_client.create_collection(collection_name=COLLECTION_NAME, schema=schema)
print(f"成功创建 Collection: '{COLLECTION_NAME}'")
print("Collection 结构:")
print(milvus_client.describe_collection(collection_name=COLLECTION_NAME))
# 5. 准备并插入数据
print(f"\n--> 正在向 '{COLLECTION_NAME}' 插入数据")
data_to_insert = []
for image_path in tqdm(image_list, desc="生成图像嵌入"):
vector = encoder.encode_image(image_path)
data_to_insert.append({"vector": vector, "image_path": image_path})
if data_to_insert:
result = milvus_client.insert(collection_name=COLLECTION_NAME, data=data_to_insert)
print(f"成功插入 {result['insert_count']} 条数据。")
# 将缓存写入更新
milvus_client.flush(collection_name=COLLECTION_NAME)
# 6. 创建索引
print(f"\n--> 正在为 '{COLLECTION_NAME}' 创建索引")
index_params = milvus_client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="HNSW",
metric_type="COSINE",
params={"M": 16, "efConstruction": 256}
)
milvus_client.create_index(collection_name=COLLECTION_NAME, index_params=index_params)
print("成功为向量字段创建 HNSW 索引。")
print("索引详情:")
print(milvus_client.describe_index(collection_name=COLLECTION_NAME, index_name="vector"))
milvus_client.load_collection(collection_name=COLLECTION_NAME)
print("已加载 Collection 到内存中。")
# 7. 执行多模态检索
print(f"\n--> 正在 '{COLLECTION_NAME}' 中执行检索")
query_image_path = os.path.join(DATA_DIR, "dragon", "query.png")
query_text = "一条龙"
query_vector = encoder.encode_query(image_path=query_image_path, text=query_text)
search_results = milvus_client.search(
collection_name=COLLECTION_NAME,
data=[query_vector],
output_fields=["image_path"],
limit=5,
search_params={"metric_type": "COSINE", "params": {"ef": 128}}
)[0]
retrieved_images = []
print("检索结果:")
for i, hit in enumerate(search_results):
print(f" Top {i+1}: ID={hit['id']}, 距离={hit['distance']:.4f}, 路径='{hit['entity']['image_path']}'")
retrieved_images.append(hit['entity']['image_path'])
# 8. 可视化与清理
print(f"\n--> 正在可视化结果并清理资源")
if not retrieved_images:
print("没有检索到任何图像。")
else:
panoramic_image = visualize_results(query_image_path, retrieved_images)
combined_image_path = os.path.join(DATA_DIR, "search_result.png")
cv2.imwrite(combined_image_path, panoramic_image)
print(f"结果图像已保存到: {combined_image_path}")
Image.open(combined_image_path).show()
milvus_client.release_collection(collection_name=COLLECTION_NAME)
print(f"已从内存中释放 Collection: '{COLLECTION_NAME}'")
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除 Collection: '{COLLECTION_NAME}'")
上面的代码包含从本地知识库文件夹构建milvus的collection以及对应的schema,同时再创建便于检索的索引,最后query采用文本+图片的形式嵌入查询,最后返回查询的top-5结果。
检索知识库内容:

代码运行结果:

代码运行结果输出:
E:\miniconda3\envs\all-in-rag\Lib\site-packages\timm\models\layers\__init__.py:48: FutureWarning: Importing from timm.models.layers is deprecated, please import via timm.layers
warnings.warn(f"Importing from {__name__} is deprecated, please import via timm.layers", FutureWarning)
--> 正在初始化编码器和Milvus客户端...
--> 正在创建 Collection 'multimodal_demo'
已删除已存在的 Collection: 'multimodal_demo'
Schema 结构:
{'auto_id': True, 'description': '多模态图文检索', 'fields': [{'name': 'id', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': True}, {'name': 'vector', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 768}}, {'name': 'image_path', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 512}}], 'enable_dynamic_field': False}
成功创建 Collection: 'multimodal_demo'
Collection 结构:
{'collection_name': 'multimodal_demo', 'auto_id': True, 'num_shards': 1, 'description': '多模态图文检索', 'fields': [{'field_id': 100, 'name': 'id', 'description': '', 'type': <DataType.INT64: 5>, 'params': {}, 'auto_id': True, 'is_primary': True}, {'field_id': 101, 'name': 'vector', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 768}}, {'field_id': 102, 'name': 'image_path', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 512}}], 'functions': [], 'aliases': [], 'collection_id': 460812018843024145, 'consistency_level': 2, 'properties': {}, 'num_partitions': 1, 'enable_dynamic_field': False, 'created_timestamp': 460856938364403715, 'update_timestamp': 460856938364403715}
--> 正在向 'multimodal_demo' 插入数据
生成图像嵌入: 100%|██████████| 7/7 [00:01<00:00, 3.72it/s]
成功插入 7 条数据。
--> 正在为 'multimodal_demo' 创建索引
成功为向量字段创建 HNSW 索引。
索引详情:
{'M': '16', 'efConstruction': '256', 'metric_type': 'COSINE', 'index_type': 'HNSW', 'field_name': 'vector', 'index_name': 'vector', 'total_rows': 7, 'indexed_rows': 7, 'pending_index_rows': 0, 'state': 'Finished'}
已加载 Collection 到内存中。
--> 正在 'multimodal_demo' 中执行检索
检索结果:
Top 1: ID=460812018840764543, 距离=0.9466, 路径='../../data/C3\dragon\query.png'
Top 2: ID=460812018840764537, 距离=0.7443, 路径='../../data/C3\dragon\dragon02.png'
Top 3: ID=460812018840764541, 距离=0.6851, 路径='../../data/C3\dragon\dragon06.png'
Top 4: ID=460812018840764538, 距离=0.6049, 路径='../../data/C3\dragon\dragon03.png'
Top 5: ID=460812018840764540, 距离=0.5360, 路径='../../data/C3\dragon\dragon05.png'
--> 正在可视化结果并清理资源
结果图像已保存到: ../../data/C3\search_result.png
已从内存中释放 Collection: 'multimodal_demo'
已删除 Collection: 'multimodal_demo'3. 索引优化
3.1 上下文拓展
3.1.1 问题背景:
由于在当前的RAG系统中出现了一个分块大小和检索精度之间权衡的问题
- 如果分块太小,虽然检索精度会明显提升,但是小块文本缺乏足够的上下文,可能导致大语言模型(LLM)无法生成高质量的答案
- 如果分块太大,虽然上下文丰富,却容易引入噪音,降低检索的相关性
为了解决这一矛盾,Llamaindex提出了一种索引策略——句子窗口检索(Sentence Window Retrieval)
3.1.2 主要思路
句子窗口检索的思想可以概括为:为检索精确性而索引小块,为上下文丰富性而检索大块。
其工作流程如下:
- 索引阶段:在构建索引时,文档被分割成单个句子。每个句子都作为一个独立的“节点(Node)”存入向量数据库。同时,每个句子节点都会在元数据(metadata)中存储其上下文窗口,即该句子原文中的前N个和后N个句子。这个窗口内的文本不会被索引,仅仅是作为元数据存储。
- 检索阶段:当用户发起查询时,系统会在所有单一句子节点上执行相似度搜索。因为句子是表达完整语义的最小单位,所以这种方式可以非常精确地定位到与用户问题最相关的核心信息。
- 后处理阶段:在检索到最相关的句子节点后,系统会使用一个名为
MetadataReplacementPostProcessor的后处理模块。该模块会读取到检索到的句子节点的元数据,并用元数据中存储的完整上下文窗口来替换节点中原来的单一句子内容。 - 生成阶段:最后,这些被替换了内容的、包含丰富上下文的节点被传递给LLM,用于生成最终的答案。
3.1.3 代码实现
下面我们基于一个Llamaindex官网的示例,来演示如何实现句子窗口检索与常规检索方法进行对比. 下面代码将会加载一份PDF格式的IPCC气候报告,并就其中的专业问题提问
import os
from llama_index.core.node_parser import SentenceWindowNodeParser, SentenceSplitter
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.deepseek import DeepSeek
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
# 1. 配置模型
Settings.llm = DeepSeek(model="deepseek-chat", temperature=0.1, api_key=os.getenv("DEEPSEEK_API_KEY"))
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en")
# 2. 加载文档
documents = SimpleDirectoryReader(
input_files=["../../data/C3/pdf/IPCC_AR6_WGII_Chapter03.pdf"]
).load_data()
# 3. 创建节点与构建索引
# 3.1 句子窗口索引
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
sentence_nodes = node_parser.get_nodes_from_documents(documents)
sentence_index = VectorStoreIndex(sentence_nodes)
# 3.2 常规分块索引 (基准)
base_parser = SentenceSplitter(chunk_size=512)
base_nodes = base_parser.get_nodes_from_documents(documents)
base_index = VectorStoreIndex(base_nodes)
# 4. 构建查询引擎
sentence_query_engine = sentence_index.as_query_engine(
similarity_top_k=2,
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
],
)
base_query_engine = base_index.as_query_engine(similarity_top_k=2)
# 5. 执行查询并对比结果
query = "What are the concerns surrounding the AMOC?"
print(f"查询: {query}\n")
print("--- 句子窗口检索结果 ---")
window_response = sentence_query_engine.query(query)
print(f"回答: {window_response}\n")
print("--- 常规检索结果 ---")
base_response = base_query_engine.query(query)
print(f"回答: {base_response}\n")
检索结构:
查询: What are the concerns surrounding the AMOC?
--- 句子窗口检索结果 ---
回答: There is low confidence in the quantification of changes in the Atlantic meridional overturning circulation (AMOC) during the 20th century due to limited agreement between reconstructed and simulated trends. Observational records since the mid-2000s are too short to determine the contributions of internal variability, natural forcing, and anthropogenic forcing to AMOC changes. Over the 21st century, the AMOC is expected to decline under all scenarios, though an abrupt collapse before 2100 is not anticipated.
--- 常规检索结果 ---
回答: The concerns surrounding the AMOC (Atlantic Meridional Overturning Circulation) primarily involve its projected decline throughout the 21st century under all Shared Socioeconomic Pathway (SSP) scenarios. While an abrupt collapse before 2100 is not expected, there is high confidence in a continued weakening. However, the observational records since the mid-2000s are too short to clearly separate the roles of internal variability, natural forcing, and human-induced forcing in these changes.
同时我还是输出对比了相关操作所需时间。
其中加载文档耗时45.78s
句子窗口检索:
窗口划分耗时2s(由于这步无限趋近于线性遍历,可视为O(n)操作需要2s)
窗口句子向量索引构建耗时263.37s
常规检索方法:
常规划分分块耗时1.92s
基础向量索引构建耗时126.63s
检索结果耗时对比:
句子窗口检索耗时11.40s
常规检索结果耗时6.52s
3.2 结构化索引
3.2.1 问题背景
随着知识库的规模不断扩大(例如,包含数百个PDF文件),传统的RAG方法(即对所有文本块进行top-k相似度搜索)会遇到瓶颈。当一个查询可能只与其中一两个文档相关时,在整个文档库中进行无差别的向量搜索,不仅效率低下,还容易被不相关的文本块干扰,导致检索结果不精确。
3.2.2 主要思路
为了解决这个问题,一个有效的方法是利用结构化索引。其原理是在索引文本块的同时,为其附加结构化的元数据(Metadata)。这些元数据可以是任何有助于筛选和定位信息的标签,例如:
- 文件名
- 文档创建日期
- 章节标题
- 作者
- 任何自定义的分类标签
这种利用元数据先过滤,缩小检索范围,再搜索的策略就是我们目前要实现的结构化索引功能。LlamaIndex 提供了包括“自动检索”(Auto-Retrieval)在内的多种工具来支持这种结构化的检索范式。
3.2.3 代码实现
在更复杂的场景中,结构化数据可能分布在多个来源中,例如一个包含多个工作表(Sheet)的 Excel 文件,每个工作表都代表一个独立的表格。在这种情况下,需要一种更强大的策略:递归检索3。它能实现“路由”功能,先将查询引导至正确的知识来源(正确的表格),然后再在该来源内部执行精确查询。
下面使用一个包含多个工作表的电影数据 Excel 文件(movie.xlsx)来演示,其中每个工作表(如 年份_1994, 年份_2002 等)都存储了对应年份的电影信息。
import os
import pandas as pd
from llama_index.core import VectorStoreIndex
from llama_index.core.schema import IndexNode
from llama_index.experimental.query_engine import PandasQueryEngine
from llama_index.core.retrievers import RecursiveRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.llms.deepseek import DeepSeek
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
# 配置模型
Settings.llm = DeepSeek(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"))
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh-v1.5")
# 1.加载数据并为每个工作表创建查询引擎和摘要节点
excel_file = '../../data/C3/excel/movie.xlsx'
xls = pd.ExcelFile(excel_file)
df_query_engines = {}
all_nodes = []
for sheet_name in xls.sheet_names:
df = pd.read_excel(xls, sheet_name=sheet_name)
# 为当前工作表(DataFrame)创建一个 PandasQueryEngine
query_engine = PandasQueryEngine(df=df, llm=Settings.llm, verbose=True)
# 为当前工作表创建一个摘要节点(IndexNode)
year = sheet_name.replace('年份_', '')
summary = f"这个表格包含了年份为 {year} 的电影信息,可以用来回答关于这一年电影的具体问题。"
node = IndexNode(text=summary, index_id=sheet_name)
all_nodes.append(node)
# 存储工作表名称到其查询引擎的映射
df_query_engines[sheet_name] = query_engine
# 2. 创建顶层索引(只包含摘要节点)
vector_index = VectorStoreIndex(all_nodes)
# 3. 创建递归检索器
# 3.1 创建顶层检索器,用于在摘要节点中检索
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
# 3.2 创建递归检索器
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever},
query_engine_dict=df_query_engines,
verbose=True,
)
# 4. 创建查询引擎
query_engine = RetrieverQueryEngine.from_args(recursive_retriever)
# 5. 执行查询
query = "1994年评分人数最少的电影是哪一部?"
print(f"查询: {query}")
response = query_engine.query(query)
print(f"回答: {response}")
这段代码的思路确实可以概括为 用 RAG(Retrieval-Augmented Generation)思路来缩小待检索的范围,然后把最相关的表格交给大模型做更深入的推理。
具体流程拆开看就是这样:
- 为每个工作表创建摘要节点(IndexNode)
- 每张 Excel 工作表都生成一句话的摘要(比如“1994 年的电影信息”),这就是顶层检索的“语义入口”。
- 同时,还为每张表构建一个
PandasQueryEngine,负责在选中的 DataFrame 内执行自然语言查询。
- 构建顶层向量索引 (VectorStoreIndex)
- 把所有的摘要节点放进一个向量索引里。
- 查询时,先通过语义检索找到最相关的表(这里设置
similarity_top_k=1,只取最相关的那一张)。
- 递归检索器 (RecursiveRetriever)
- 顶层检索器负责选出表。
- 选出的表会“递归”到对应的
PandasQueryEngine,由它把自然语言问题转化为具体的 DataFrame 查询。
- 最终执行查询
- 用户问的问题(比如“1994年评分人数最少的电影是哪一部?”),会先用摘要节点缩小范围到
1994的表。 - 然后把完整的
1994表 DataFrame 交给PandasQueryEngine,由它调用大模型生成 SQL-like 查询并执行,最后再返回结果。
- 用户问的问题(比如“1994年评分人数最少的电影是哪一部?”),会先用摘要节点缩小范围到
运行结构:
INFO:sentence_transformers.SentenceTransformer:Load pretrained SentenceTransformer: BAAI/bge-small-zh-v1.5
Load pretrained SentenceTransformer: BAAI/bge-small-zh-v1.5
INFO:sentence_transformers.SentenceTransformer:1 prompt is loaded, with the key: query
1 prompt is loaded, with the key: query
加载表格耗时 0.3888511657714844
子表初始化耗时 0.06314826011657715
创建向量耗时 0.45253634452819824
查询: 1994年评分人数最少的电影是哪一部?
Retrieving with query id None: 1994年评分人数最少的电影是哪一部?
Retrieved node with id, entering: 年份_1994
Retrieving with query id 年份_1994: 1994年评分人数最少的电影是哪一部?
INFO:httpx:HTTP Request: POST https://api.deepseek.com/chat/completions "HTTP/1.1 200 OK"
HTTP Request: POST https://api.deepseek.com/chat/completions "HTTP/1.1 200 OK"
> Pandas Instructions:
```
df[df['编号'].isin([2, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100])].nsmallest(1, '评分人数')['电影名称'].iloc[0]
```
> Pandas Output: 阳光灿烂的日子
Got response: 阳光灿烂的日子
INFO:httpx:HTTP Request: POST https://api.deepseek.com/chat/completions "HTTP/1.1 200 OK"
HTTP Request: POST https://api.deepseek.com/chat/completions "HTTP/1.1 200 OK"
回答耗时 22.59388256072998
回答: 阳光灿烂的日子但是由于这个代码中存在由数据库直接执行LLM生成的查询代码,存在安全风险,我们可以改为优化结构,让LLM亲自过滤,而不是执行代码查询,当然这需要LLM具有”一定的思维能力“