Code Graph Model (CGM): A Graph-Integrated Large Language Model for Repository-Level Software Engineering Tasks
对应开源代码库:
github:https://github.com/codefuse-ai/CodeFuse-CGM
huggingface:https://huggingface.co/codefuse-ai/CodeFuse-CGM-72B
摘要
考虑到虽然企业开发的专属大模型智能体在某些领域具有高SOTA,但是由于其闭源性以及token限制等等问题,本文论证了基于开源大模型解决仓库级代码的可行性。最后本文提出了Code Graph Model(CGM)的概念,CGM主要有两个方面的特定:
1.将仓库级代码图结构融入到大语言模型的注意力机制
2.通过一个专门的适应器将点属性映射到LLM的输入空间
最后结合一个无代理的图RAG(Retrieval-Augmented Generation)检索增强生成框架最后在漏洞检测相关数据集SWE-bench上达到了比较优秀的效果。
相关工作
针对code方面的LLM
闭源LLM的上下文长度限制,以及数据安全性存在问题。
开源LLM通过预训练基于拓扑分类后的仓库代码,将会面临两个主要问题,一个是仓库代码长度过长,另一个是将仓库结构保存为文本格式往往会造成显式依赖关系丢失。
为了克服这些挑战,作者提出了将仓库表示为富文本图(text-rich graph),同时通过连续自监督预训练完成该图与LLM的对齐。
Text-rich Graphs 是指节点或边中含有丰富自然语言文本内容的图结构。
Text-rich graphs 同时具备以下两种信息:
- 结构信息(Graph structure):
- 通过节点与边连接的图结构(如依赖图、调用图、知识图谱等)。
- 语义信息(Textual information):
- 图中的节点(有时边)附带较长或复杂的文本,例如句子、代码片段、文档标题等。
代码语言模型中的图
将图结构融入代码语言模型可以主要分为三种方法:
1.attention mask modification
例如GraphCodeBERT (Guoet al., 2020)and StructCoder (Tipirneni et al., 2024)通过修改注意力mask使其获取在AST和DFG中代码词元间的关系
Attention Mask Modification:融合的核心思想
Transformer 的 Attention 是通过计算每个 token 对其他 token 的注意力权重来实现上下文建模的。默认的 attention 是对输入序列中的所有位置都开放,即每个 token 能“看到”所有其他 token。
而 Attention Mask Modification 的本质,是利用图结构修改 Transformer 的 Attention 连接,让 Token 之间的 Attention 更符合图结构的连接关系。
具体实现步骤
步骤 1:构建图结构(如 AST)
使用静态分析工具(如 Joern、tree-sitter、pyast、JDT 等)将源代码解析为图:
- 节点:如变量名、操作符、函数名等 token。
- 边:如语法边(AST),控制边(CFG),数据边(DDG),可根据具体任务选取。
步骤 2:对齐图节点与代码 Token
Transformer 输入是 token 序列(如经过 BPE 分词后的代码 Token),而图是以语义节点为单位的。所以需要:
- 建立 图节点 ↔ Token Index 的映射;
- 一种常见做法是让图的节点以 token 为单位,或将图的语义节点映射到其所在的 token 的起始位。
步骤 3:构建 Modified Attention Mask
创建一个与输入长度一致的 attention mask 矩阵
A:plaintext复制编辑A[i][j] = { 1 if token_i 可以看到 token_j (有图结构连接) 0 否则 }
- 如果原始 Transformer 是完全连接(即 A[i][j] = 1 ∀ i, j),
- 则现在改成仅允许根据图结构连接的 token 之间有注意力。
可选策略:
- 硬 Attention Mask(Hard Mask):完全屏蔽非图边连接的 attention;
- 软 Attention Bias(Soft Mask / Bias):对图中相连节点给予更高的注意力分数(如加权)。
举个例子:
原 attention mask(BERT): for i in range(10): [CLS] for i in range ( 10 ) : [SEP] ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ 所有 token 都能看到所有 token 图 attention mask: 只允许 AST 中相连的 token 之间建立 attention e.g., 'for' 只能看 '(', 'range', ':'
实际融合策略
方式一:Attention Mask 替换
将原始的全连接 Attention Mask 替换为图构建的邻接矩阵(A)。
- 适用于 BERT encoder 类型的结构;
- 训练阶段直接使用 Mask 进行注意力控制;
- 代表工作:
- SynCoBERT (ICLR 2022):使用 AST 修改 attention。
- CodeBERT with Graph:GraphCodeBERT 使用 Data Flow Graph 辅助训练,但也有使用 AST 结构修改 attention 的后续变体。
方式二:Multi-Head Graph Bias(Soft Attention)
为 attention score 添加图结构的 bias 项:
Attention(Q, K, V) = softmax(QKᵀ / √d + B) V其中 B[i][j] 是 graph bias:
- 如果 token i, j 在图中有边,则 B[i][j] = learnable positive bias;
- 否则为 0 或负值;
- 可学习地鼓励模型关注图结构。
代表工作:
- GTuner (ICML 2023):在 Transformer 中融合语法图和数据流图,通过 soft bias 调整 Attention。
举例说明
假设我们有如下代码:
a = 5 b = a + 1 print(b)AST 中可能的边:
a→5(赋值)b→a,1,+(加法操作)b(函数调用)构造的 Attention Mask:
a = 5 b + 1 ( b ) a 1 1 1 0 0 0 0 0 0 0 b 1 0 0 1 1 1 0 0 0 0 … 只有图结构中有关联的 token 才能互相关注。
2.graph-to-text conversion
第二种方法是图到文本的转化,例如 TreeBERT (Jiang et al., 2021)and UniXcoder (Guo et al., 2022)。
比如将ASTs或者节点路径转化为可以直接被语言模型处理的文本序列。
具体例子:
假设我们有一段 Python 代码:
a = b + c(1) 构建 AST(抽象语法树)
解析成 AST(简化示意):
Assign ├── Name(a) └── BinOp(+) ├── Name(b) └── Name(c)这个结构是树状的,LLM 原本不能直接吃。
(2) 转化成文本(两种方法举例)
方法 A:直接前序遍历(TreeBERT 类似思路)
我们用前序遍历,把节点类型按顺序列出来,加一些括号来保留层次:
Assign ( Name a ) ( BinOp + ( Name b ) ( Name c ) )这就是一串 token,LLM 可以直接处理。
方法 B:节点路径(UniXcoder 类似思路)
从 AST 中提取节点路径(node paths),每个路径描述两个节点之间的关系。比如:
a → Assign → ba → Assign → cb → BinOp → c把这些路径线性化为文本:
a Assign b; a Assign c; b BinOp c这种方法用多个“小句子”表示结构关系。
(3) 送进语言模型
不管是 TreeBERT 的括号结构,还是 UniXcoder 的节点路径句子,最终都是token 序列,可以直接喂进 BERT、GPT 等 Transformer 模型进行训练或推理。
类比理解
- 原始 AST 就像一棵树(结构化的、分支很多)。
- LLM 就像一个人,他只能读一行一行的文字,不能直接“看”树形图。
- “图到文本转化”就是把树按某种规则排成一行行的文字,让他能照着文字还原出树的结构信息。
3.positional encoding augmentation
第三种方法例如TPTrans (Peng et al., 2021),利用相对位置编码去表示AST的结构化关系。
具体例子:
假设有一段 Python 代码:
a = b + c
(1) AST 结构
AST(简化版):
Assign ├── Name(a) └── BinOp(+) ├── Name(b) └── Name(c)
(2) 普通 Transformer 的绝对位置编码
如果直接按前序遍历转成序列:
[Assign, Name(a), BinOp(+), Name(b), Name(c)]
- 绝对位置编码可能是:
Assign → pos 0 Name(a) → pos 1 BinOp(+) → pos 2 Name(b) → pos 3 Name(c) → pos 4这样模型只能知道“Name(a) 在 Assign 之后、BinOp 之前”,却不知道它是 Assign 的子节点。
(3) TPTrans 的相对位置编码
TPTrans 会根据 AST 的结构计算节点之间的相对距离,作为位置编码输入到注意力机制中,例如:
Node1 Node2 相对位置类型 Assign Name(a) 父 → 子 Assign BinOp 父 → 子 BinOp Name(b) 父 → 子 BinOp Name(c) 父 → 子 Name(a) BinOp 兄弟节点 Name(b) Name(c) 兄弟节点 Assign Name(c) 父 → 孙子
相对位置不只是距离,还包括方向(parent→child / child→parent)和类型(同层、父子、祖先等)。
这些信息会被编码成一个相对位置向量,在 Transformer 的注意力权重计算中加入:
$\text{Attention}(Q, K) = \frac{Q K^T + R_{rel}}{\sqrt{d_k}}$
其中 $R_{rel}$ 就是相对位置编码矩阵。
(4) 效果
- 模型不只是按顺序看 token,而是能感知“Name(a) 是 Assign 的左孩子”、“Name(b) 和 Name(c) 是兄弟节点”。
- 这样对于代码理解、生成任务,模型能更好地利用 AST 的结构信息。
类比理解
- 绝对位置编码像是在阅读一行文字:你只能说“这个词是第 5 个”。
- 相对位置编码(AST 版)像是在看一张家谱:你知道“这个人是某人的父亲/兄弟/祖先”,哪怕他们在名单里不是紧挨着。
针对软件工程的智能体驱动方法
传统基于大模型的智能体已经通过他们的交互能力和推理能力证明了他们解决现实世界软件工程问题的能力。同时沿着这个思路,研究者已经尝试了各种加强大模型智能体的方法,包括
专门化智能体电脑接口,
细粒度搜索
拓展行动空间
1. 专用 Agent‑Computer Interface(ACI)
典型代表:SWE‑agent(Yang 等人 2024b)、ScreenAgent(Wang 等人 2024b)
- SWE‑agent:为 LLM 代理构建专门设计的接口,让它们能够深入操作代码文件、浏览仓库结构,以及执行测试与编程任务。这不仅提供了多维度的环境感知,还能及时反馈执行结果,从而显著提升其改错与编程的效率,实验证明其在 HumanEvalFix 测试中通过率达到 87.7%,远超标准 LLM 效果 arXiv。
- ScreenAgent:通过截图 + GUI 接口,将视觉语言模型与鼠标键盘行为输出绑定,让代理能够真实操控操作系统。它在“规划→执行→反思”周期内不断迭代,保障了对界面位置的精确控制,并在多步骤日常任务中展现了与 GPT‑4V 相近的性能 arXiv。
总结:ACI 方法用专门设计的软件桥梁,将 LLM 的“思考”能力与计算/图形界面“行动”能力结合起来,使代理具备真实操作电脑系统的能力。
2. 细粒度检索(Fine‑Grained Search)
代表工作:PaSa、Fine‑Grained Optimization (FGO)
- PaSa(Yao 等,2024b):针对学术搜索任务,PaSa 由两个子代理构成:Crawler 自动调用检索工具并扩展引用,Selector 针对候选文献进行细粒度筛选,形成闭环流,通过 RL 训练实现高精度查询 ResearchGate+1arXiv+1。
- Fine‑Grained Optimization (FGO):将大任务拆解为小子任务(如 ALFWorld、LogisticsQA 等),分别优化后再合并,一方面降低 LLM 的 prompt 长度,另一方面优化效率与准确率,提升 1.6–8.6% 性能,同时减少约 56% token 消耗 openreview.net。
总结:细粒度检索方法强调将复杂任务拆解,通过 LLM 与检索/搜索工具配合,实现精确独立子任务优化与组合,提高整体准确率与效率。
3. 扩展动作空间(Expanded Action Spaces)
代表:OpenDevin(Wang 等,2024c)
- OpenDevin:该平台为代理开放更多可执行动作类型,包括但不限于代码编辑、知识库检索、工具调用等。其设计允许作为“通用开发者代理”,在多样化的软件开发情境全流程作业,可跨项目协作、自选行动,有效提升代理对复杂任务的处理能力 ijcai.org。
总结:此类方法扩大 LLM 代理的可控域,让其可触达更多工具 / 操作,从而具备开发者级别的综合任务执行能力。
但是上面的方法仍然存在一些不足
1.首先虽然他们通常直接授权智能体去决定行动的时机和性质,尽管智能体会根据之前的行为和环境反馈来做出决定,但是由于拓展的行为空间和复杂的反馈机制可能会导致重复行为,错误累计,最终导致次优解
例子:LLM 代理进行自动软件调试任务
任务背景:
LLM 代理要在一个大型代码仓库中自动修复一个运行时报错的 Python 函数。它拥有以下“动作空间”:
- 可以运行程序获取报错栈信息;
- 可以搜索 StackOverflow;
- 可以编辑任意代码文件;
- 可以重新运行单元测试;
- 可以修改测试用例;
- 可以调用调试工具(如 print/log);
- 可以在日志中插入错误追踪点;
- 还可以调用多个插件,比如 GPT-4 进行辅助分析。
问题出现:
由于动作空间大,代理尝试以下行为:
- 第一次修改函数参数名后报错仍在 →
- 搜索 StackOverflow 并做了第二次修改 →
- 运行后产生新的错误 →
- 增加 print 调试信息 →
- 根据 print 信息又进行了新的尝试修改 →
- 重复上述过程 5 次……
由于:
- 它没有意识到早期的假设是错误的;
- 每一步操作的结果反馈是延迟且非结构化的(运行报错信息);
- 每次反馈都被误解成新方向的“合理提示”,
最终:
- 代理在有限时间内进行了大量“无效修复”,
- 产生了累积错误(对多个无关位置做出误操作),
- 浪费 token 和调用次数,
- 最终产生了一个结构更混乱、甚至功能退化的版本(即“次优解”)。
2.其次解决一个问题通常需要30~40轮交互,使得整个过程非常耗时同时使得特定轮中的识别复杂化,最终导致不满意的结果
3.同时智能体行为的内在固有的不可预测性以及对闭源模型的依赖为利用数据提高性能创造了障碍。
针对软件工程的无智能体方法
相比与依赖大模型智能体去自主决策或者使用负责工具,无智能体方法提供了一个更加可控的方法通过遵守明确、固定的步骤去仿真现实世界的软件工程过程。它有助于避免不可预测性和冗长的交互链问题。
方法主要操作在两个阶段,本地化和编辑
1.本地化阶段将会明确同一个仓库中相关联的代码片段
2.编辑阶段阶段生成或者修改代码基于已识别部分。
这个框架与RAG结合对于仓库级代码完成任务尤其有效。
同时尽管检索的时候使用了图结构,但是现有的方法通常将检索到的代码片段展开为线性文本序列作为下游模型的提示词。图转文本的过程中损失了其图之间的异质性和文本模式。
代码图构建
在深入代码图之前,理解代码图大模型所使用的仓库级代码图以及其构建的过程是非常重要的。代码图的主要目的是在复杂的代码基础中提取其内在的结构和语义信息的结构化表示。
其中每一个仓库表示为一个有向图$G = (V,E)$
其中该定义包括7种节点和5种边:
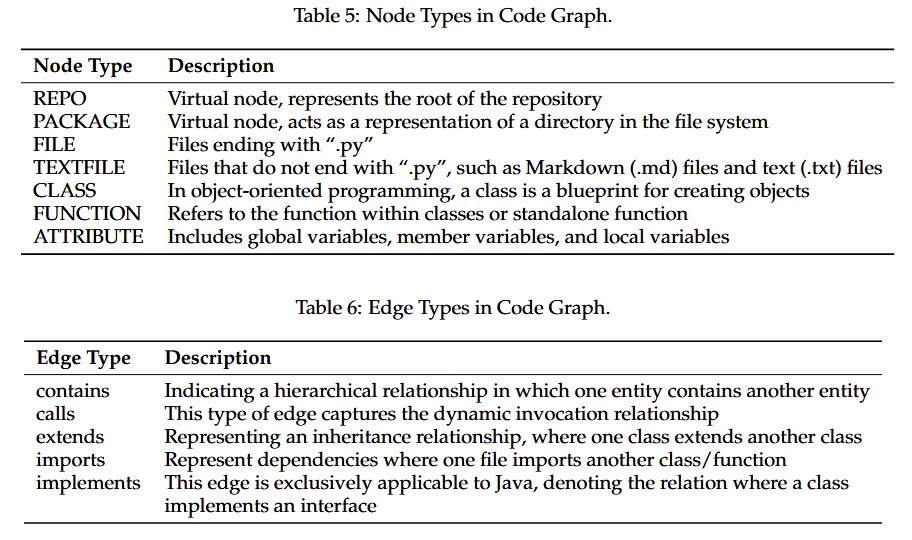
当前只应用在了python和java上。
代码图模型
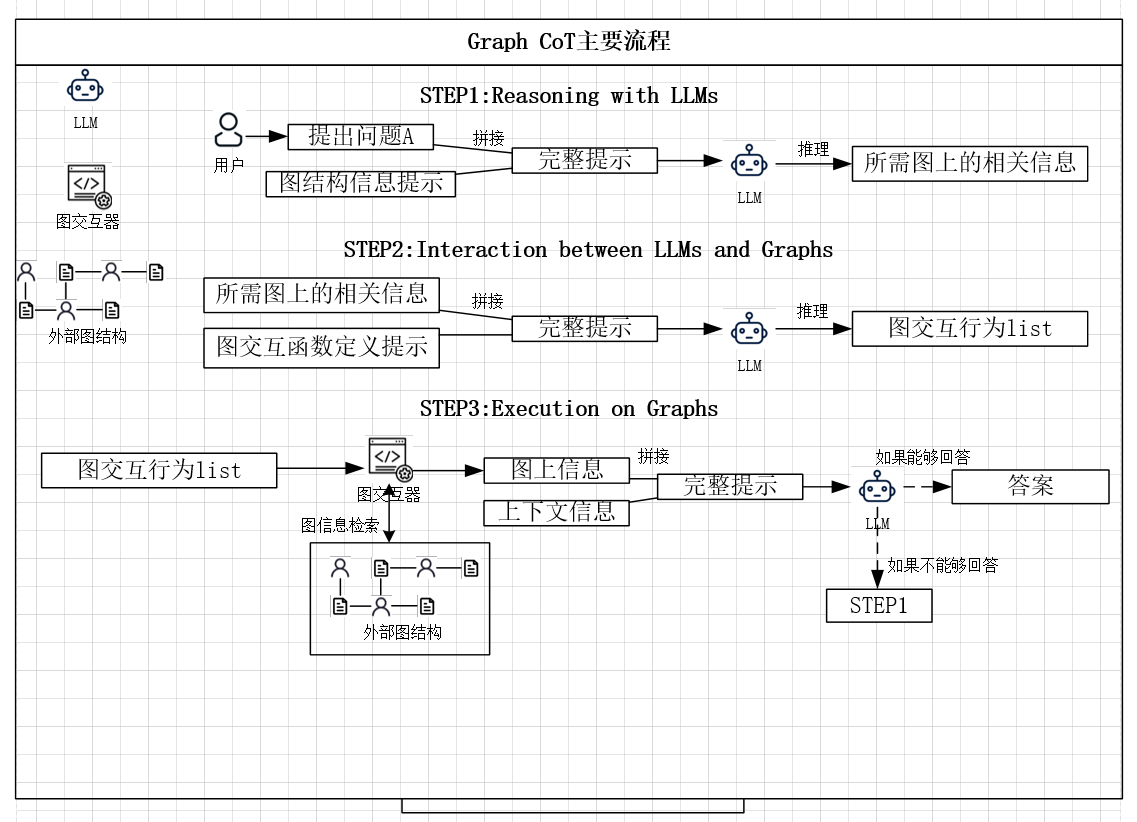
下来详细介绍代码图的工作流程:
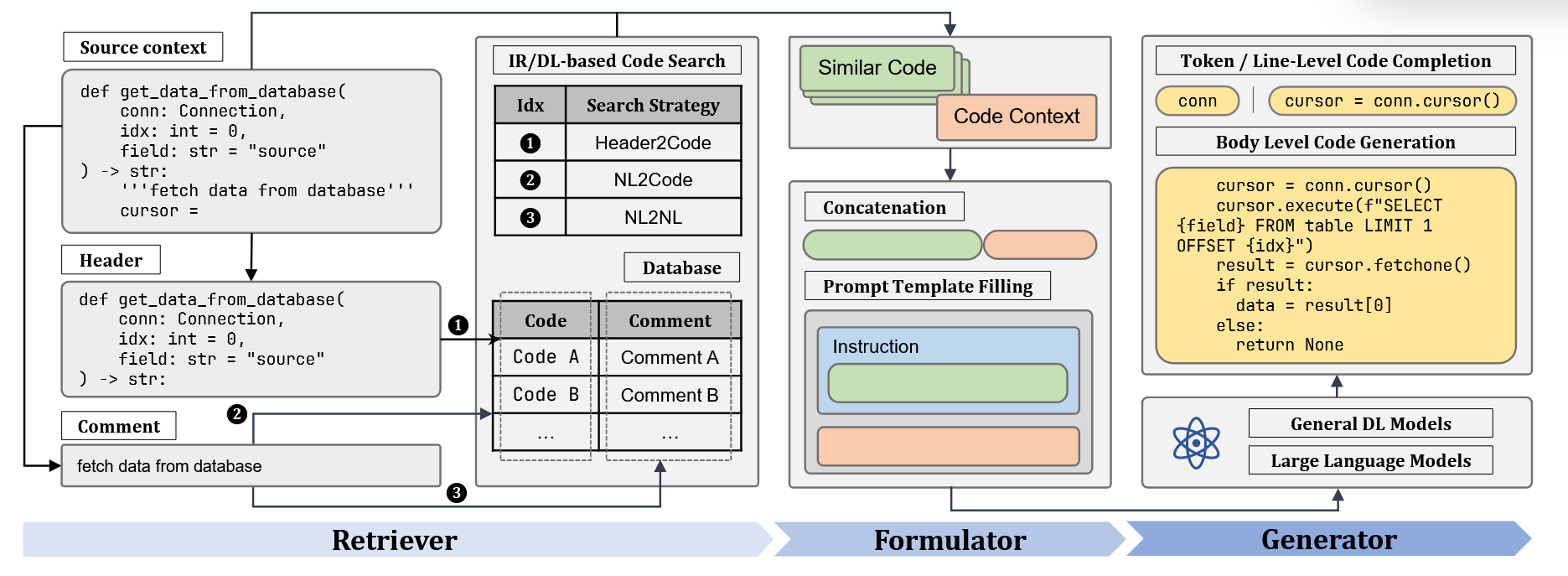
上面代码图的主要流程
a.Rewriter
首先抽取器(Extractor)会先根据当前的提问提取出对于的代码实体和关键词,接着推断器(Inferer)将会修正原提问为更细节查询。
b.Retriever
然后检索器从对应的代码图中定位相关的节点,同时通过连接邻居和上游节点拓展这些节点为连通子图。
c.Reranker
接着重排器将分为两个阶段去对检索结构排序
1.文件名排序
2.文件框架排序
该部分将会选择综合排序中最相关的文件进行修改。
d.CGM
最后代码图模型将基于检索得到图和选择得到的文件作为输入。同时每个节点的节点内容被编码器$\varepsilon$ 编码,然后通过一个适应器$\mathcal{A}$ 生成对应节点词元。接着在进入大模型解码器$\mathcal{D}$之前,节点词元将和文本词元串联之后作为提示,同时该邻接矩阵将替代器原始注意力掩码。(相当于限制各词元间的可见度,只有图上相邻才可见)
模型框架
接下来部分将详细介绍CGM是如何整合语义与结构化信息进大模型的。
语义融合
首先我们需要明确代码图的富语义是体现在仅在节点蕴含的文本内容
该部分的节点信息融合主要流程为
$节点信息\rightarrow编码器(encoder)\rightarrow适应器(adapter)\rightarrow解码器(decoder)$
编码器部分(encoder):这里使用到的预训练的编码器是CodeT5+,为了解决节点包含的文本上限长度,作者将每个节点的内容划分为每512tokens一个从chunks,每个chunks独立编码。同时为了保证图的一致性,还需要为每个chunk复制源节点,同时每个复制节点需要保持相同的外边关系,同时每个复制节点内部需要保持全连接关系。同时其文本顺序关系由位置编码来保持。
具体例子:
假设你有一个图结构的节点 Node A,它的内容是:
"Graph neural networks (GNNs) are a class of neural networks designed to perform inference on data described by graphs. They can capture both the graph structure and the features of nodes, edges, and the entire graph…"
这个节点的内容有 1024 tokens(假设统计过)。
由于编码器一次只能处理 512 tokens,我们按规则拆成两个 chunk:
- Chunk A1:第 1–512 个 token
- Chunk A2:第 513–1024 个 token
图结构调整过程
复制节点
原图里只有一个 Node A,跟其他节点(比如 Node B、Node C)有一些边:
Node A — Node B Node A — Node C拆分后,我们得到两个新节点:
Node A1 (第1块) Node A2 (第2块)这两个节点都 继承 Node A 的连接:
Node A1 — Node B Node A2 — Node B Node A1 — Node C Node A2 — Node C同一节点内部全连接
为了让两个 chunk 能互相传递信息,还要加上:
Node A1 — Node A2顺序信息
在 LLM 解码器里,我们通过位置编码告诉模型:
Pos(Node A1) < Pos(Node A2)这样模型知道它们在原文中是有先后顺序的,而不是两个独立的内容。
直观理解
- 想象 Node A 是一本书的一章,太长了放不进扫描仪(encoder)。
- 于是你把它分成两页(chunk A1 和 chunk A2)分别扫描。
- 扫描的时候,你告诉系统:
- 这两页都来自同一本书的同一章节(保持连接)。
- 这两页彼此相关(全连接)。
- 第一页在第二页之前(位置编码)。
这样,即使章节被拆开处理,后续解码器也能正确地“拼”回原来的意思。
适应器部分(adapter):
在编码器和LLM解码器之间,由于编码器的输出维度不一定和解码器的输入嵌入层维度相同,为了将编码器的输出映射到解码器输入的嵌入空间,我们中间需要需要一个维度调整的适应层。
具体样例:
假设你有一个系统:
- Encoder:BERT 变种,用来处理文本 + 图结构信息,输出维度
768。- LLM:LLaMA-2,词嵌入维度
4096。如果直接把 BERT 的
768维输出扔进 LLaMA-2,会不匹配(矩阵相乘的形状不对),所以我们加一个 adapter:less复制编辑BERT输出: [batch_size, seq_len, 768] → 适配器A: 两层MLP + GELU - 第1层: Linear(768 → 1536) - GELU 激活 - 第2层: Linear(1536 → 4096) → LLaMA-2 输入嵌入空间: [batch_size, seq_len, 4096]例子场景:
- 你有一个图文混合数据(比如科研论文的节点和内容),BERT 编码器负责先理解图结构和文本信息,生成 768 维特征。
- Adapter 把这些特征转成 LLaMA-2 能接收的 4096 维格式。
- LLaMA-2 再利用这些特征进行文本生成(摘要、问答等)。
类比理解
Adapter 就像一个 插头转换器:
- 你的笔记本(encoder)电源插头是英式三孔(768维)。
- 你的插座(LLM)是美式两孔(4096维)。
- Adapter 就是那个转换插头,把形状/规格转成匹配的,不然就插不上去。
接着在把对应chunk的embedding喂给解码器之前,作者还将每个512-token的chunk压缩为1-token,比如取整个token的池化平均或者取开头的[cls]作为压缩。这种压缩有效地将LLM的上下文长度扩展了512倍,从而能够处理大规模代码库的上下文。
具体例子:
假设我们有一个大型代码仓库,有一个文件内容如下(简化版):
# utils.py (部分代码) def load_data(path): with open(path) as f: return f.read() def preprocess(text): text = text.lower() return text.strip() # ... 还剩下很多代码 ...这个文件总共有 10,240 个 token。
编码器限制一次只能处理 512 token → 所以我们分成 20 个 chunk:Chunk 1 → tokens 1–512 Chunk 2 → tokens 513–1024 ... Chunk 20 → tokens 9729–10240
压缩过程
编码器处理每个 chunk
- Chunk 1 → 一个 768 维向量
- Chunk 2 → 一个 768 维向量
- …
- Chunk 20 → 一个 768 维向量
压缩成单个 node token
每个 chunk 的 512 个 token → 压缩成一个向量(node token),比如直接取编码器的[CLS]向量或用平均池化。
结果:
NodeToken1 (代表 Chunk1 的全部语义) NodeToken2 (代表 Chunk2 的全部语义) ... NodeToken20送进 LLM 解码器
- 原来 LLM 4,000 token 限制 → 只能看大约 4,000 个原始 token。
- 现在 1 个 node token ≈ 512 原始 token → 4,000 node token ≈ 2,048,000 原始 token。
- 这样它就可以处理一个超大规模代码库的全局上下文。
类比理解
你可以把这个压缩过程想象成:
- 原始文本的 512 个 token 是 一段非常长的故事。
- 压缩后变成 一句简明摘要(node token)。
- LLM 不看所有细节,而是用这些摘要来推理全局。
这样它就可以记住更多的“故事章节”,不会因为容量限制丢上下文。
结构融合
传统方法试图通过将代码片段线性化为序列来整合仓库级别的结构信息,但这种转换往往无法保留代码实体之间的显式关系,为了更好地维护结构关系,作者引入了一个图感知注意力掩码,代替了传统的时序注意力掩码(第n个只能看见前n个)
具体例子:
假设我们有一个代码依赖图(非常简化):
Node A: utils.py (分成两个 chunk → A1, A2) Node B: data.py (分成一个 chunk → B1) Node C: main.py (分成两个 chunk → C1, C2)代码依赖关系(原始节点层面)是:
A → B (utils 依赖 data) B → C (data 依赖 main) A → C (utils 依赖 main)
节点复制后
因为 A 和 C 很长,我们按 512 token 分 chunk,复制成多个 node token:
A1, A2 (都继承 A 的外部边,并且 A1 ↔ A2 全连接) B1 (只有一个 chunk) C1, C2 (都继承 C 的外部边,并且 C1 ↔ C2 全连接)
邻接矩阵(graph-aware)
根据上面的依赖和副本关系,我们得到 node token 层面的邻接矩阵(只画部分关系):
A1 A2 B1 C1 C2 A1 1 1 1 1 1 A2 1 1 1 1 1 B1 1 1 1 1 1 C1 1 1 1 1 1 C2 1 1 1 1 1 (这里是全 1 只是因为例子依赖很密集,实际中会有很多 0)
Graph-aware Attention Mask 作用
传统 causal mask:
A1 只能看 A1 A2 只能看 A1, A2 B1 只能看 A1, A2, B1 C1 只能看 A1, A2, B1, C1 ...它忽略了图结构,只按 token 顺序来。
graph-aware mask:
- 如果 A1 和 B1 在图中有边,就允许 A1 ↔ B1 的注意力;
- 如果没有边,就把对应的 attention 分数设为 -∞(屏蔽掉);
- 对于 A1 ↔ A2、C1 ↔ C2(同一个原节点的不同 chunk),总是允许全连接。
这样,LLM 在处理 node token 时,只会关注与它有图结构关系的节点,保留了代码依赖的信息。
总体思路
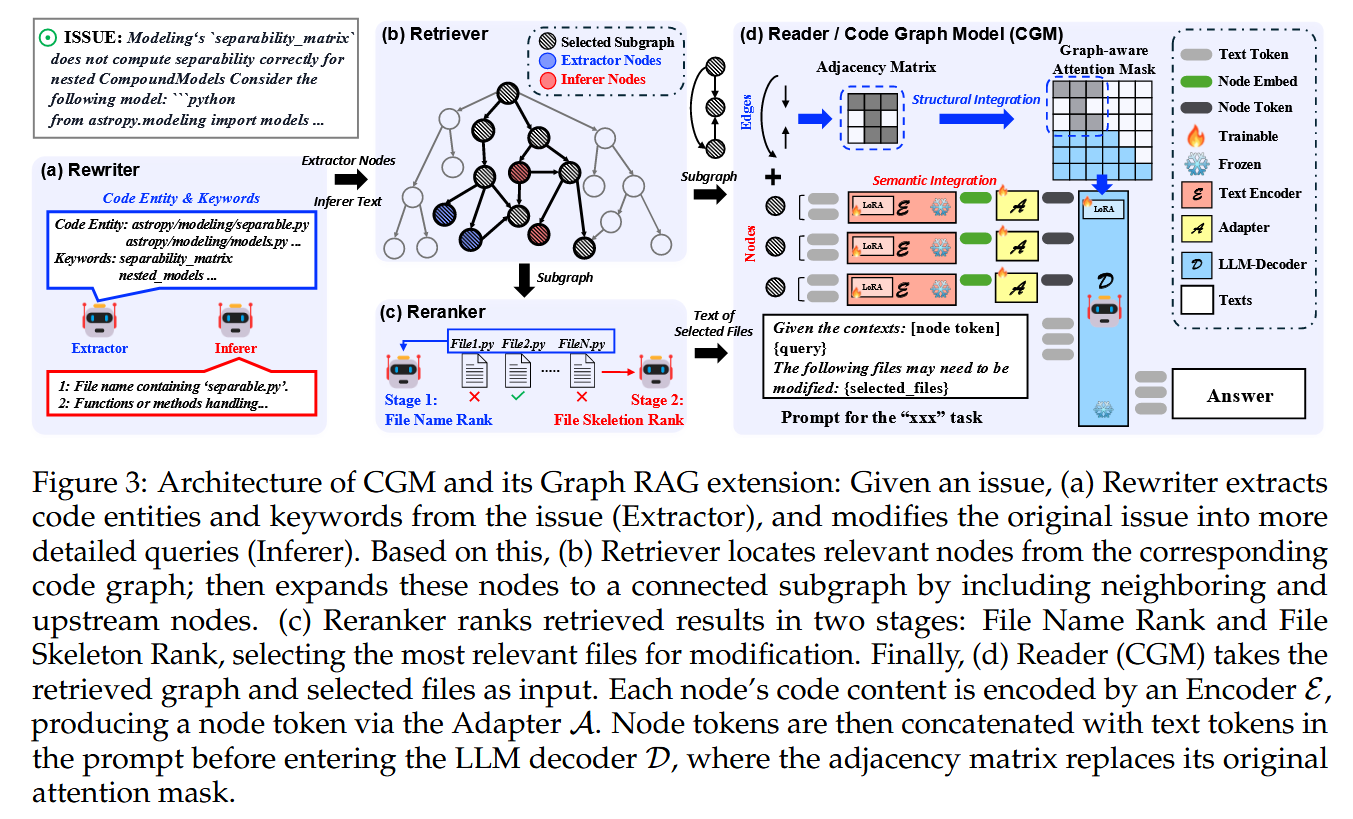
Graph RAG 有 四个核心模块,按顺序执行:
- Rewriter(重写器)
- Retriever(检索器)
- Reranker(重排序器)
- Reader(阅读器 / CGM 本身)
这样形成一个从用户问题到代码补丁的端到端流水线。
相比一些复杂的方案(如 Xia et al., 2024 里的 10 步流程),Graph RAG 的架构很紧凑,效率高。
(1) Rewriter
作用:优化用户原始问题描述,方便后续模块精准检索代码。
内部有两个子组件:
- Extractor(提取器):从用户问题中抽取关键代码元素,比如文件名、函数名、关键词。
- Inferer(推理器):补充更多语义信息,丰富功能描述,让检索更精准。
比如:
用户问题:"修复
process_data()在data_utils.py中的索引错误"Extractor:
data_utils.py,process_data,索引错误
Inferer:描述它是在处理 CSV 文件时,索引越界导致程序崩溃。
(2) Retriever
作用:根据 Rewriter 的结果,在代码图(Code Graph)中构造一个连通子图。
步骤:
- 找到 Extractor 节点(蓝色)→ 用字符串匹配定位代码元素。
- 找到 Inferer 节点(红色)→ 用语义检索(CGE-Large 模型)找出语义相似的节点。
- 扩展到这些节点的一跳邻居(捕捉局部依赖关系)。
- 确保子图与根节点 REPO 连接(保证全局上下文可达)。
- 每个文件节点(FILE)会展开成内部所有节点,方便后面 Reranker 做文件级分析。
结果:得到一个针对用户问题的仓库增强子图(repository-enhanced context subgraph)。
(3) Reranker
作用:从 Retriever 得到的子图中,筛出最可能需要修改的文件(避免无关文件)。
步骤:
- 初选:根据原始问题和文件名,选出 K = 10 个可能相关文件。
- 精筛:基于文件 skeleton(代码结构摘要)与问题的相关性打分,选出 K = 5 个最相关的文件。
(4) Reader(CGM)
作用:生成最终的代码补丁。
输入:
- 子图(node tokens,黑色) → 提供全局代码依赖信息。
- 被选文件的完整代码(text tokens,灰色) → 提供局部细节。
两部分信息通过一个 prompt 模板结合,送进 LLM(CGM)生成响应。
技术细节
- Rewriter 和 Reranker 用的是开源大模型 Qwen2.5-72B-instruct。
- Retriever 的语义搜索 用的是 CGE-Large。
- 框架在附录中提供了:
- D:一个完整案例(从零解决一个真实 issue)。
- C.4:计算成本,包括构建代码图的成本。
- F:具体 prompt 细节。
流程举例
假设用户问题是:
“修复当输入 JSON 缺少字段时
parse_config()崩溃的 bug。”
Graph RAG 会这样做:
- Rewriter
- Extractor:提取
parse_config、JSON 缺少字段 - Inferer:补充“缺少字段时抛出 KeyError 导致应用启动失败”
- Extractor:提取
- Retriever
- 匹配到
config_utils.py里的parse_config节点(蓝色) - 语义检索到相关的 JSON 解析节点(红色)
- 扩展一跳邻居,如调用方和依赖的文件
- 形成连通子图
- 匹配到
- Reranker
- 初选:
config_utils.py,app_loader.py,settings.py等 - 精筛:发现
config_utils.py和app_loader.py最可能改动
- 初选:
- Reader
- 输入子图 + 相关文件全文
- 输出修改后的代码补丁
后续论文阅读补全方向
1.长上下文建模能力提升相关
1.E2llm: Encoder elongated large language models for long-context understanding and reasoning.
2.Lloco: Learning long contexts offline.
3.FocusLLM: Precise Understanding of Long Context by Dynamic Condensing.