Datawhale AI夏令营第二期baseline达标笔记
前言:
基于想快速过一遍基础大模型中的数据蒸馏,以及模型微调等等相关基础流程,正好看到Datawhale AI夏令营第二期报名开始了,于是借着本次夏令营的机会,好好正式入门大模型相关技术。
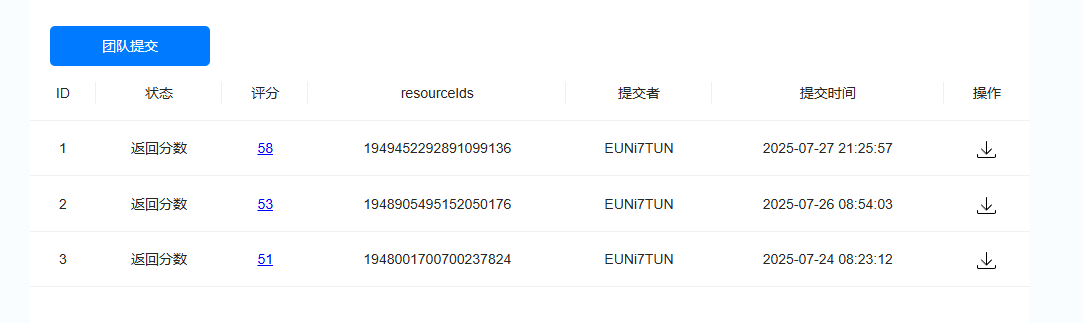
由于原指导文件已经非常详细了,这里参考:科大讯飞AI大赛(大模型技术) – Datawhale,所以这里我们只分析部分代码解释和个人改进部分。本次个人达标baseline分数为58分。
任务介绍
当前有一个xlsx文件,里面是是一个列车时刻表结构化数据,数据量在200条左右,其中里面的字段包括包含“序号”、“车次”、“始发站”、“终到站”、“到点”、“开点”、“候车厅”、“检票口”、“站台”等信息。
我们当前需要微调一个大模型,让其完成对应旅客关于列车时刻表的相关问题的问答任务,最后评估指标将会按照:
- 答案准确率(AS):40%权重
- 回答响应时长(ART):30%权重
- 回答信息传达效率(AE):30%权重
思路分析
显然我们最终的目标是训练出一个熟悉列车时刻表的大模型,当有游客向这个大模型询问相关的列车表问题时,大模型可以准确的回答。
显然我们需要使得一个LLM掌握这个列车时刻表的大模型,同时还得尽可能保留这个大模型的知识库和推理能力,这里特别介绍LoRA微调。
LoRA(Low-Rank Adaptation)是一种参数高效微调方法,它不修改 LLM 原有的大量参数,只在某些层(如 attention 的 Q/K/V 或 FFN)中插入小矩阵进行训练。
优点包括:
- 不破坏原始模型知识的基础上兼容新知识库
- 快速、高效、低资源训练
- 可插拔、适用于多任务
所以我们明确是需要使用Lora对某个已有大模型进行微调,由于在这次实验我们将基于科大讯飞平台对该模型进行微调,同时由于Lora具体细节已经被平台内部封装好,我们只需要提供微调模型,训练数据集,训练参数。
同时我介绍一下Lora 微调常见的数据集格式:
1. Alpaca 格式(指令微调标准)
{ "instruction": "请告诉我感冒时应该注意什么?", "input": "", "output": "感冒时应注意多休息,保持室内通风,多喝水..." }
instruction:用户给模型的指令input:补充上下文信息(可为空)output:模型预期生成内容2. ShareGPT 格式(多轮对话)
[ {"from": "human", "value": "今天天气怎么样?"}, {"from": "gpt", "value": "今天天气晴朗,温度适中。"}, {"from": "human", "value": "适合出门吗?"}, {"from": "gpt", "value": "非常适合,可以安排户外活动。"} ]
- 多轮问答
- 适合训练多轮对话能力
由于不能直接将xlsx文件喂给大模型微调,这里显然我们需要使用Alpaca格式的数据集完成微调。
显然我们首先需要先基于xlsx完成对应Alpaca格式数据集的生成,接着在科大讯飞平台上完成对应基础模型的选择,然后导入数据集,最后调整训练参数,最后完成训练,接下来我将结合代码进行详细介绍。
具体实现
数据集生成
首先我们先考虑如何生成对应Alpaca 格式的数据集,这个部分我们将会使用数据蒸馏,我们主要思路是先基于xlsx文件构造生成相关的问题数据集,然后将这个xlsx转为字符串,作为信息源,加上我们已经构造好的问题集一起喂给一个“老师模型” ,接着我们将这个“老师模型”回答的答案和问题集一起构造对应的Alpaca 格式的数据集
具体代码实现如下:
import pandas as pd
import requests
import re
import json
from tqdm import tqdm
# 读取数据
data = pd.read_excel('info_table.xlsx')
data = data.fillna('无数据')
data上面的代码是先读入xlsx文件,然后完成空缺内容的填充
def create_question_list(row: dict):
"""
根据一行数创建问题列表
Args:
row: 一行数据的字典形式
Returns:
list: 问题列表
"""
question_list = []
# ----------- 添加问题列表数据 begin ----------- #
# 检票口
question_list.append(f'{row["车次"]}号车次应该从哪个检票口检票?')
# 站台
question_list.append(f'{row["车次"]}号车次应该从哪个站台上车?')
# 目的地
question_list.append(f'{row["车次"]}次列车的终到站是哪里?')
#起点
question_list.append(f'{row["车次"]}次列车的始发站是哪里?')
#到点
question_list.append(f'{row["车次"]}次列车的到点是什么时候?')
#开点
question_list.append(f'{row["车次"]}次列车的开点是什么时候?')
#候车厅
question_list.append(f'{row["车次"]}次列车的候车厅在哪?')
# ----------- 添加问题列表数据 end ----------- #
return question_list上面的函数的作用是基于xlsx文件格式完成对应问题集相关问题的字符串字段拼接问题构造。
# 简单问题的prompt
prompt = '''你是列车的乘务员,请你基于给定的列车班次信息回答用户的问题。
# 列车班次信息
{}
# 用户问题列表
{}
'''
def call_llm(content: str):
"""
调用大模型
Args:
content: 模型对话文本
Returns:
list: 问答对列表
"""
# 调用大模型(硅基流动免费模型,推荐学习者自己申请)
url = "https://api.siliconflow.cn/v1/chat/completions"
payload = {
"model": "Qwen/Qwen3-32B",
"messages": [
{
"role": "user",
"content": content # 最终提示词,"/no_think"是关闭了qwen3的思考
}
]
}
headers = {
"Authorization": "Bearer 你的模型api",
"Content-Type": "application/json"
}
resp = requests.request("POST", url, json=payload, headers=headers).json()
# 使用正则提取大模型返回的json
print(resp)
content = resp['choices'][0]['message']['content'].split('</think>')[-1]
pattern = re.compile(r'^```json\s*([\s\S]*?)```$', re.IGNORECASE) # 匹配 ```json 开头和 ``` 结尾之间的内容(忽略大小写)
match = pattern.match(content.strip()) # 去除首尾空白后匹配
if match:
json_str = match.group(1).strip() # 提取JSON字符串并去除首尾空白
data = json.loads(json_str)
return data
else:
return content
return response['choices'][0]['message']['content']这里由于我们利用和远程大模型基于api交流,所以我们需要了解对应平台的api消息定义,这里我使用的数据蒸馏的模型是Qwen3-32B,对应的官方api文档定义是创建对话请求(OpenAI) – SiliconFlow
上面函数的主要作用是将构造的背景信息+问题集发给“老师模型”,然后接受对应模型处理之后的标准问答。这个过程即为数据蒸馏的粗蒸馏过程。
这里由于接受到的答案文本还不是结构化的,我们不方便后续处理,同时也不符合Alpaca 格式,接下来我们将进一步使用特定的prompt提示大模型输出我们期待格式的输出,如下代码所示:
output_format = '''# 输出格式
按json格式输出,且只需要输出一个json即可
```json
[{
"q": "用户问题",
"a": "问题答案"
},
...
]
```'''接下来就是我们遍历我们构造的问题集,让大模型输出标准格式的输出,然后将其以json的格式保存到本地文件中即可,这便是数据蒸馏的全过程
train_data_list = []
error_data_list = []
# 提取列
cols = data.columns
# 遍历数据(baseline先10条数据)
i = 1
for idx, row in tqdm(data.iterrows(), desc='遍历生成答案', total=len(data)):
try:
# 组装数据
row = dict(row)
row['到点'] = str(row['到点'])
row['开点'] = str(row['开点'])
# 创建问题对
question_list = create_question_list(row)
# 大模型生成答案
llm_result = call_llm(prompt.format(row, question_list) + output_format)
# 总结结果
train_data_list += llm_result
except:
error_data_list.append(row)
continue
print(question_list)
print(train_data_list)
# 转换训练集
data_list = []
for data in tqdm(train_data_list, total=len(train_data_list)):
if isinstance(data, str):
continue
data_list.append({'instruction': data['q'], 'output': data['a']})
json.dump(data_list, open('single_row_1.json', 'w', encoding='utf-8'), ensure_ascii=False)
print(len(data_list))
data_list[:2]
Lora微调
这里在科大讯飞平台我们选择的基础模型是Qwen3-8B,接着我们将我们上一步生成的数据集导入,最后按照默认参数完成训练即可。
初步效果